
21 line poem ending Lewis Carroll's 'Alice's Adventures in Wonderland'.
First letters (an acrostic) of the 21 lines spell the name of the real Alice,
'Alice Pleasance Liddell'
My related essay Who Wrote Shakespeare? is
Go to homepage
Preamble
Early
Shakespeare decoding was total nonsense
Historically
hidden messages are a fact
What
about the dedication to the Shakespeare sonnets?
Are
recent published findings and odds calculations correct?
An
astronomical number of possible words?
Introduction
Sonnet
and funerary monument cryptograms
Shakespeare
sonnet dedication is very short
Are
the hidden texts real?
Shakespeare
in the bible --- not all 'hidden' text is a cryptogram
Shakepeare
sonnet dedication cryptogram
Who
is 'Henry Wriothesley'?
Facsimile
of Sonnet dedication
Rollett's
sonnet dedication paper (1999)
Three
texts in dedication
My
reading of x18
1)
Order is correct
2)
Read only down
Rollett's
x18 reading
Estimate
of the odds
Letter
frequency in sonnet dedication text
Is
the long name Rollett found in an 18x8 grid of the dedication real?
One
five letter fragment
Three
two letter fragments
Four
fragments in correct order
x18
result
Reduction
#1 -- multiple spacings
Reduction
#2 -- other fragment combinations
Reduction
#3 -- other relevant words
Shakespeare
funerary monument cryptogram?
Is
the stone engraving original?
The
claim
Reduced
message
Critical
look at Shakespeare funerary monument poem
Odds
of 'Vere'
Raw
look at x34
Calculating
the probability of key words
Two
letter words
Appendix I
David
Roper on Rollett's sonnet dedication
x19
discussion
Give
me a break!
Roper
on 'Henry'
Roper's
odds calculation
Errors
in Roper's odds calculation
Appendix II
One
way to spell 'Henry Wriothesley'?
Appendix III
Monument
trial runs
Appendix IV
Ten
monument decode trials
Appendix V
Notes
on Latin lines of Shakespeare funerary monument text
Is
Æ one character or two?
Appendix VI
Four
old versions of the monument poem: 1631, 1656, 1721, 1825
Four
poem versions compared line by line
Importance
of 1825 version --'sith' not 'sieh'
Appendix VII
Shakespeare
monument poem images
Appendix VIII
History
of the Shakespeare monument
Appendix IX
Woolpack
man?
Dugdale's
'woolpack' sketch from another perspective
Adding
a feather
Appendix X
Stratford
monument poem -- first write up
Appendix XI
Some
acrostic messages are real
Appendix XII
Overview
of probability vs word length
Appendix XIII
Equidistant
vs grid decoding
Words
that span two columns
Appendix XIV
Prof
Albert Burgstahler's view
Appendix XV
Baconian
decoding is all nonsense
Friedmans'
Shakespearean cipher book
'Some
Acrostic Signatures', by William Stone Booth, 1923
Bacon
'Bote-swaine' cipher
Appendix XVI
Ben
Jonson's First Folio poem --- an elaborate Cryptogram?
Appendix XVII
Shakespearean
spelling
Appendix XVIII
Critical
look at sonnet 76
Summary
The
focus of this essay is to assess mathematically the strength of
two recent claims that two different Shakespearean documents have been
found to be cryptograms. This is not a pro-Oxford or pro-Marlowe screed.
I just want to know if any of the recently discovered 'hidden' texts are
real.
The two candidate cryptograms examined, both dated from the time of Shakespeare,
but neither written by Shakespeare, are
Dedication to the Shakespeare Sonnets --- 1609
Shakespeare funerary monument poem in Trinity church --- 1616 to 1623
Dedication to the Shakespeare Sonnets
Is the Dedication
to the Shakespeare Sonnets a cryptogram? The math definitely says yes!
A name related to the sonnets pops out whose strongest elements are two
five
letter strings. Because each contain a rare letter, the odds of each
string (alone) is about 1,000 to 1. There is also a confirming hint with
the text being rather odd and its layout keying a hidden, relevant phrase.
Shakespeare funerary monument poem in Trinity church
Is the Shakespeare
funerary monument poem in Trinity church a cryptogram? Maybe (maybe
yes, maybe no). The math can only take us so far in this case because the
output is a phrase not a name, however the odds of the words in the phrase
can be calculated. A phrase relevant to authorship pops out whose strongest
elements are two four letter strings. However, the math of four
letter strings that are composed of common letters is not compelling. For
example, the odds of the string 'Vere' plus 'e' and 'de' appearing by chance
(at some spacing) is 10%. 'e' is a very common letter. The other four letter
string, 'test', is composed of even more common letters.
The odds are moderately improved (factor of 33 or so) if two hints can be relied on that decoding should be done using x34 spacing. One hint is that 34 is an integer multiple of 17 and Edward de Vere was the 17th Earl of Oxford. This is clean. The other hint is the number of characters in the only indented line is 34, but this hint is valid only if Æ is counted as one letter. The engraved text on the monument is full of combined letters and all (but Æ) need to be expanded for the cryptogram to work. So this hint hinges on whether Æ (in Latin) is one letter or two. A very technical question. Dr. Spittle, who found this hint, says Æ is a single letter in Latin, but Wikipedia says that Æ in Medieval Latin was an optional ligature (in effect two letters), so there is some measure of doubt about this hint.
Another problem is whether the engraved monument text is really from Shakespeare's time. It is a fact that in the first two hundred years of its existence the text on the monument was recorded three known times, and in all three of these cases the cryptogram fails. For example, all three observers wrote 'monument', not 'monvment', deleting the 'v' in 'Vere', killing the key word for the Oxfordians. For the funerary monument text to be a hidden message from Shakespeare's time all three observers who recorded the text had to have done so inaccurately! Now this may very well have been the case given the flexibility of Elizabethan spelling, but still it introduces some level of doubt.
The odds of its words forming a phase that is both relevant and (crudely) grammatical is hard to evaluate mathematically, but still it adds to the strength of the argument that it is a cryptogram. (The claim is made by Roper that the phase is grammatical, but this is achieved by moving things around.) There is also some confirmation in that the funerary monument text has some odd features, like inconsistent spellings and the famous phase, 'read if thou can't'.
Preamble
As a retired
engineer, I know enough mathematics to understand that recent claims that
cryptograms
have been found and solved in some early short documents closely associated
with Shakespeare should not be dismissed out of hand. In this essay I focus
on the strongest cases where the decoding is simple, just reading with
skips (no letter reversals, no wild jumping around, no X's, S's, diagonals,
or arrows, no mathematically weak, undisciplined and discredited deciphering
like the Baconians used in years past to discover Bacon's name hidden in
Shakespeare's works).
When the hidden text discovered turns out to be a name, probability calculations based on letter counts are possible. In cases where the hidden text is a phrase probability must be estimated from empirical tests and auxiliary factors. When the odds (correctly calculated) come out to be high, say 10,000 to 1 (or higher), which in at least one case they do, then I am convinced that the hidden text discovered is probably real, that it was deliberately, and at great effort, encrypted into these documents 400 years ago. It is hard data.
Early
Shakespeare decoding was total nonsense
Beginning
in the 1880's the followers of Francis Bacon wrote a huge number of books
claiming that they had found hidden messages within Shakespeare's works
proving that Bacon was the author. The impetus for all this decoding was
that Bacon had written about codes, even inventing one himself (Bacon biliteral
cipher). In 1957 professional cryptographers William and Elizabeth Friedman
in 1957 wrote a classic book, Shakespearean Ciphers Examined, that
exposed all the Baconian decoding work of the previous 70 years as nonsense.
Author after author had combed through Shakespeare's plays using a variety
of elaborate, pliable decoding rules, inconsistently and imaginatively
applied, such that almost any 'message' could be read out. There is no
evidence that the Bacon's biliteral cipher was ever used to hide messages
in books of the time, and while in theory it was usable, in practice
it was not, because it was not compatible with the sloppy printing practices
of the 16th century. (My long Amazon review of the Friedmans' book here.)
This early (Baconian) work gave Shakespearean ciphers (and cryptograms) a very bad reputation that has lingered. However, some newer (Oxfordian) work is in a different class, using simple decoding applied to short documents with odds that are calculable. The best of it might even be valid!
Historically
hidden messages are a fact
The early
search for hidden messages in Shakespeare, while poorly carried out, was
not crazy, because historically hidden messages in works of literature
are a fact, they do exist. The Friedman's book gives some examples of real
hidden messages. Edgar Allen Poe in an 1846 poem called, 'The Valentine',
hid the full name of a woman he was attracted to while both were still
married to other people. One letter from each line of his 20 line poem
taken in order (following a strict formula called a progressive acrostic)
spells out her name: 'Frances Sargent Osgood' (exactly 20 letters). Another
mathematically convincing case is a 53 letter (simple) acrostic from a
work published anonymously in 1616, the year the First Folio was
published. The first letter of each of the 53 sections of the book taken
in order spells out (in Latin): 'Franciscus Godwinvvs Landavensis Episcopus
hos conscripsit' (exactly 53 letters), which in English is 'Francis Goodwin,
Bishop of Llandaff, wrote these lines'. So here we have an historical example
from Shakespeare's time of an author who really did hide his name within
the text!
Another example of real hidden text (not from the Friedman book) occurs in the famous book 'Alice's Adventures in Wonderland', where its author (Lewis Carroll) coded in the name of the little girl that inspired the book, often known as the 'real Alice'. String together the first letters of 21 consecutive lines (technically an acrostic) of a poem at the end of the book, and it spells out 'Alice Pleasance Liddell', the full 21 letter name of a little girl Carroll knew and often photographed! Mathematically these cases are all slam dunks, 20 or more letters in a row yielding a relevant name or phrase will simply not arise by chance in this universe. Here is the Alice poem.
What about the dedication to the Shakespeare sonnets?
21 line poem ending Lewis Carroll's 'Alice's Adventures in Wonderland'.
First letters (an acrostic) of the 21 lines spell the name of the real Alice,
'Alice Pleasance Liddell'
Here is a summary of why I find the decode of the 'Dedication to Shakespeare's Sonnets' done in 1997 by Dr. John M. Rollett is so interesting:
1) Text is very short, only 144 letters
2) The sonnet dedication text and format are both very odd (period after
every word, and a strange line format). It has been
suspected for years that it might be a cryptogram.
3) Decode procedure is simple, just write out the text on graph paper, read down (or up/down)
4) Decode fragments (pieced together) yield a 16 letter full name (Henry Wriothesley)
5) Name found is relevant to the sonnets (leading candidate for W. H.)
6) Odds of a specific name arising by chance can be calculated, because
it requires a specific sequence of letters, and letter frequency
of the dedication is known exactly (by counting).
7) Five letter first name ('Henry') and five letter fragment of last name
('esley') each contain a 'y', and there is only one 'y' in the 144 letters
of the dedication.
8) The odds of a specific five letter name (or string) with a 'y' is about
1,000 to 1, which makes the odds of two five letter strings
(in same name, both with a 'y') about a million to one.
9) The line format and word-periods taken as key to a word skip decode
yield a grammatical phrase possibly relevant to the author
of the sonnets. ('These sonnets all by ever (E. Ver)'). A possible 2nd
cryptogram in the same 144 letters.
Are
recent published findings and odds calculations correct?
Not always.
There are odds calculations out there that are misleading or plain wrong.
Some researchers in the field are quite conservative, while others let
their imagination run free 'seeing' complex and fanciful patterns and phrases
that I find hard to take seriously. One mathematically correct, but
misleading approach, is to calculate the odds only of exactly what
has been found rather than for the universe of (similar) possibilities.
For some perspective on all of this see the Appendix where I contrast the
work of Rollett and Roper on the 144 letter sonnet dedication.
An
astronomical number of possible words?
I know
one reason many people do not take cryptograms seriously is because they
suspect the hidden names or word arises from an astronomical number
of possible words (letter combinations). A well known Shakespeare book
author told me this was one reason he avoided all cryptograms. For a long
document like the Bible astronomical may not be too far off the
mark, but for short documents this is simply not the case. For texts of
a few hundred letters the number of combinations is measured in thousands.
When documents are very short, the chances that a relevant long name or phrase will arise by chance is very small. This is why in this essay I focus on two very short documents with text of only 144 letters (sonnet dedication) and 220 letters (Shakespeare monument poem). Mathematically these are the strongest cases.
Introduction
In recent years
a few researchers have discovered previously unknown text and names that
appear to have been coded (at great effort) into short documents lauding
Shakespeare, documents that were written while he was alive or soon after
his death. The texts revealed by the decoding are curious and interesting
and can be interpreted as clues that Shakespeare was not the true author.
If these hidden texts are 'real', meaning statistically significant, which
some of them appear to be, they should be a part of the authorship debate.
In a long document like the bible it's easy to discover lots of (supposedly) hidden messages by applying various decoding techniques. But finding text (phrases, names), which is both readable and relevant, in very short documents like the dedication to the sonnets, all of 144 letters, or the Shakespeare monument poem, only 220 letters, is a whole other ballgame. Readable and relevant text that uses a significant fraction (say 10% or so) of the available text is very, very unlikely to have arisen by accident.
Sonnet
and funerary monument cryptograms
A few short
documents from Shakespeare's time have in recent years been put forward
as being cryptograms, meaning they contain additional, hidden text
(phrases, names). These are not documents written by Shakespeare,
but documents from 400 years ago lauding him that are intimately associated
with his work or life. The two I find the most convincing mathematically
as cryptograms are:
1) 144 letter dedication to the Sonnets (1609)
2) 220 letter poem on the Shakespeare monument in Trinity Church Stratford
on Avon (1616 to 1623)
The first is signed 'T.T.', and this is generally taken to be the initials of the publisher of the sonnets (Thomas Thorpe). Wikipedia says, "Popular belief, however, is that Shakespeare is the author of the (sonnet) dedication", but no reference is given. The second is unsigned, but a favorite candidate is Ben Jonson who worked on the first folio. But in truth no one knows who wrote either one.
In a cryptogram the hidden text is only revealed when the cryptogram is solved. The first, sonnet dedication, was solved by Dr. John M. Rollett, who wrote it up in a couple of papers in the late 1990's. The second, funerary monument poem, was solved by David L. Roper, who discusses it in two recent Shakespeare books he has written and on his homepage.
What has aroused great interested in the few that have looked into these Shakespearean cryptogram is two things. One, these documents are very short and the hidden messages revealed use in the range of 10% of the letters, which it is obvious would be extremely unlikely to occur by chance. Two, the hidden texts revealed are clearly relevant and may offer clues to the solution of several Shakespearean mysteries, like who is Mr. W. H. of the sonnets and even who is the author of the works. They don't necessarily 'prove' anything, but they should be treated as real and and hard data in the authorship debate.
Shakespeare
sonnet dedication is very short
The shortest
Shakespearean (related) document that appears to be a cryptogram (with
hidden text) is the 1609 dedication to the sonnets. It is written out in
two grids below (on graph paper). Two five letter strings (marked in red)
stand out: 'Henry' and 'esley'. These are both part of the 16 letter full
name 'Henry Wriothesley', a leading candidate for W.H., and all the other
letters of his name are there too and in the correct order ('wr', 'io'
'th').
There is only one 'y' in the sonnet text, the odds of the two five letter strings marked can be calculated by multiplying out the letter frequency of the other four letters in each string. For example, there are 9 r's in the 144 letter text, so the odds that an 'r' will precede the single 'y' is [9/(144 - 1)] = 6.3%. The odds for the five letter string 'henry' come out to be about 1,000 to 1 (see below for details), and for 'esley' about 600 to 1 because it has two vowels. Making the odds of the whole name formed from two five letter strings plus the rest of the name from shorter strings at least a million to one. It's odds like this that have convinced me that this dedication (and maybe some other Shakespearean documents) was composed as a cryptogram, the solution of which reveals hidden text (name or a phrase).
 .
.
HENRY WR IO TH ESLEY
(Henry Wriothesley)
There is yet another cryptogram (probably) in this 144 letter dedication. Incredibly this short dedication was found by Dr. John M. Rollett to be a double cryptogram. The second cryptogram hides a text phrase that (possibly) points at the author of the sonnets. It is a word skip cryptogram. Here is the facsimile of the dedication in the original 1609 printing (see below for full version with 'T.T.' signature).

(reading --- 6th, 2nd, 4th words)
THESE SONNETS ALL BY EVER
(These sonnets all by E Ver)
Elizabethan typography is weird, but the typography of this one is really strange. Note, there is a period after every word! Inverted pyramid patterns are often seen in Elizabethan typography (see examples in my other Shakespeare essay, 'Who Wrote Shakespeare?'), but here that structure is oddly uncoordinated with the text. Are these two hints that this weirdly structured word pattern (typography) might be a cryptogram and here is how to solve it? Looks likeit. Reading in a pattern the 6th, 2nd, 4th, etc words (from beginning) with words indicated by the periods (and dashes) out comes: 'THESE SONNETS ALL BY EVER'.
This is not subtle. It's like the man in the moon, once pointed out it is obvious. So how come it was not until the 1997 that this was first figured out by Dr. John Rollett? Rollett in his 1999 paper (here) provides a convincing answer. He shows how almost every Shakespearean editor over the years, not understanding that this was cryptogram, slightly altered ('cleaned up') the typography and spelling when they printed the dedication in their Shakespeare editions, obliterating the cryptogram!
Are the hidden texts
real?
When I first
heard about this years ago I was intrigued, but only recently have I taken
the time to read the papers, do the decoding and calculate probabilities
myself, to see if I could convince myself if any of these hidden texts
were real. Having been trained at MIT as an EE engineer and having worked
for years with noisy systems, I think I have a leg up one most literary
types who probably don't know how to do probability calculations nor how
to assess the strength of probability claims put forward by others.
After several months of work, including reading paper of the papers of the discovers and making email contact with some of those working in the field, I am convinced that one, and maybe two, of the two documents above have (at great effort) been crafted as cryptograms, that the hidden texts found there are real, meaning they were deliberately encoded (hidden). And what makes this important is that the hidden texts are clearly relevant to Shakespeare and very interesting, perhaps providing clues to the solution of some long standing Shakespearean mysteries. I personally take no position as to what these hidden texts mean (if anything), nor do I think they 'prove' who wrote Shakespeare. My only objective in this essay is to lay out the argument that the hidden texts found in these two cases are real.
If any of these cryptogram solutions are real, which at least in one case I think statistical is very, very likely, this is hard evidence both for Shakespeare authorship problem and a mystery associated with the sonnets. Hard evidence with Shakespeare is hard to come by so it deserves to be more widely known.
As far as I can tell, cryptogram arguments are known (or understood) by only a very small group, mostly Oxfordians. I never see a mainstream reference to cryptograms nor do I find any reference to them in Shakespeare articles on Wikipedia. Some of those working on the problem put this down to mathematical illiteracy of most literary scholars. I suspect some reject cryptograms because their intuition tells them an astonomical number of possible words exist. (Not true when the text is short.) It must also be said that some decoding pushes the boundaries of reasonableness, and published odds calculations need to be taken with a grain of salt, because not only are a lot of them pulled out of the air, but some are just plain wrong (see appendex). I have had a general interest in this topic for a decade, but until recently I had only ever heard of one case (Shakespeare monument poem).
Shakespeare in the bible --- not all 'hidden' text is a cryptogram
There is (what at first appears to be) a surprising reference to Shakespeare in the King James Bible. I read that the church in Stratford where Shakespeare is buried keeps open a King James bible to Psalm 46.In 46th chapter of Psalm's count in 46 words from the beginning and you will find the word 'shake'. Then count back from the end of the same chapter 46 words (with some fudging) and you find the word 'spear'. In 1610, the year the King James is being finalized for the press, Shakespeare is age 46. With all these coincidences this had got to be deliberate, right? Isn't it obvious that this is a cryptogram, a hidden reference to Shakespeare inserted into the King James by the translators (or God!)? Well, when you did into it a little, not really.
In three earlier english bibles translated before Shakespeare was born (Great Bible of 1539, Geneva bible of 1560, and Bishops' Bible of 1568, the primary reference for the King James) 'shake' and 'spear' are already there in Psalm 46 and very close to their locations in the King James, respectively at 46/48, 48/44, 47/48. With this information the mystery and surprise is gone. From bible to bible texts vary a little all the time (note the letter count in each of the three previous bibles is different), so clearly it could easily have happened by chance. It's impossible to a non-expert to put a number on the odds, but in a letter to the London Times in 1976 by a professor of classics he details how the King James translation guidelines would indeed have shifted 47/48 spacing of the reference text to 46/46.
No mathematical rigor=======================================================================================
Clearly this is a case with no mathematical rigor. While we can't rule out it was deliberate, there is a a very good chance it happened by chance. And even if it was deliberate, it's a tiny little cryptogram requiring only one or two word substitutions. (For links and more details on this case see my general Shakespeare essay.)
The most convincing case for hidden text in early Shakespeare related documents I think is the 144 letter dedication to the Shakespeare sonnets, which was published with the sonnets in 1609. It is a double (even triple) cryptogram. At one equidistant letter spacing is found 'Henry' and at another spacing is found 'Wriothesley'. This is the first and last name of one of the two leading candidates to be mysterious W.H. of the sonnet dedication and a candidate to be the 'fair youth' of the sonnets. The odds of this particular name ('Henry' + 'Wriothesley') at any (two) equidistant spacings being real, i.e. that is not being a statistical fluke, can be rigorously calculated. In round numbers the result is
Henry (five adjacent letters) 1,000 to 1
Wriothesley
(five adjacent letter fragment 'esley')
1,000 to 1
(three two letter fragments, Wr, io, th)
10 to 1
(all four last name fragment in order)
10 to 1
---------------------------------
total 100,000,000 to 1
The odds against 5 letter 'Henry' popping up by accident is 1,000 to 1. The odds against 'Wriothesley' as a five letter fragment (1,000 to 1) plus three shorter fragments all in order (100 to 1) popping by accident is their product 100,000 to 1. Probability rules specify that probabilities, if independent, be combined by multiplication. Hence the odds of his full name ['Henry' 'Wriothesley'] appearing is the odds of the two names multiplied or 100 million to 1. The odds that all this hidden text (long full name, structured as indicated above) could have arisen by chance is as near zero as you can come in this world.
Who is 'Henry Wriothesley'?Yet there is still another cryptogram in the 144 letter dedication. This one hiding a text phrase that point at the author of the sonnets. This is a word skip cryptogram. The fact that there is a word skip cryptogram in the dedication is strongly suggested by the really strange typography used in its printing. Look at the facsimile of the original (above and below). Note, there is a period after every word (or what should be considered a word for the cryptogram)! The word skip pattern is suggested by the weird line pattern, by the line count in the three inverted triangles: 6,2,4. Reading (from beginning) 6th ,2nd, and 4th words (repeat) out comes (marked above)
Henry Wriothesley was a nobleman, the 3rd Earl of Southampton. He inherited the Earldom at age 8 when his father died and he became a ward of Lord Burghley, chief advisor of the queen, and essentially the prime minister.Lord Burghley also shows up frequently in the anti-Stratfordian world. One of his jobs was watching out for peerage orphans. Years earlier Edward de Vere, whose father died when he was 12, became a ward of Burghley. When Southampton was twenty, Burghley suggested that he marry Elizabeth Vere, daughter of Edward de Vere, Burgley's step granddaughter. De Vere's son Henry was a close friend of Southhampton. There is a 1624 painting ('Noble Henries') of them together on horseback in command of troops in Holland.When Wriothesley was age 20 in 1993, Shakespeare's long narrative poem, Venus and Adonis, was published and dedicated to him, and a year later Shakespeare's poem 'The Rape of Lucrece' was also dedicated to him. Some scholars have long thought Southampton might be the the 'fair youth' of the sonnets and/or possibly the 'W. H.' of the sonnet dedication. Maybe Burghley commissioned Shakespeare in 1590, when Southampton was age 17, to write the first seventeen sonnets encouraging him to marry (Southampton Sonnets). Southampton does marry in 1598 at age 25. Three years later (1601) he gets involved with Essex who had screwed up a military attack on Ireland and who came back to challenge the queen (Essex conspiracy). Essex has his head cut off in Tower of London, and Southampton is sentenced to death, but is saved by Burghley and is out of jail and back to court when a new king replaces the queen.Thus Southampton (Henry Wriothesley) and the older Edward de Vere are essentially family having had the same step father with De Vere's son a friend of Southampton, whereas there is no known relationship other than possibly patron, between the man from Stratford and Southampton.
These sonnets all by e ver [the forth]
It's a little stretch, but not too bad I think, to interpret 'ever' as 'e ver', or E. Vere. (I don't do anagrams, and as the Friedman's point out in their book looking for anagrams led the earlier Bacon decoders badly astray, but nevertheless it is true that 'ever' is an anagram 'vere' for what it's worth.) Curiously the 6,2,4 pattern matches the letter count in 'Edward de Vere' too. Another coincidence? Well maybe, but nonetheless suggestive. (There also a way to tie Edward de Vere to 'the forth' too say some, but I have not looked into that.) I don't see really how to really calculate the odds of a phrase like this, but the common sense and apparently relevant message arising when using the skip spacing pattern suggested strongly by the typography implies that this is very likely to have been crafted deliberately. The discover of this, John M. Rollett, said for fun over 20 years he looked at this pattern in the first paragraphs of text he was reading. He figures he did this with 20,000 paragraphs and only one did he get a reasonable looking sentence (or phase), and its meaning was totally unrelated to the document. (Good for him, he ran an experiment, the scientfic method at work.)
There you have it. Two (or three) cryptograms in one very short 144 letter dedication. The full name with its 16 letters uses 11% of the 144 letters in the sonnet, and the five words of the (shorter) phrase use 17% of its words. The two part cryptogram that reveals the name 'Henry Wriothesley' has odds that calculate out to be 100 million to one. If the the 3rd cryptogram is also considered, the word skip cryptogram that yields a readable and relevant phrase, 'These sonnets all by e ver', then I would argue that all three cryptograms together push the odds that the dedication was written deliberately as a cryptogram to -- I don't know, but it's really high! I am convinced by statistical arguments like this that some early Shakespeare related documents do contain hidden text (names and phrases) that are real, and they should be taken seriously.
So I am not misunderstood. I am not saying hidden text proves de Vere wrote Shakespeare. I am not an Oxfordian, just an anti-Stratfordian. I am only saying I know enough mathematics to be convinced that this stuff is real, that the original author(s) of these documents went to great effort to conceal some names and phrases in these documents. The mathematical odds tell us that the text we find by solving (the best of) these cryptograms was very likely to have been deliberately put there, so it should be taken as real and included in the Shakespeare authorship debate. What the hidden names and phrases mean is for others to argue about. For all I know it could be Elizabethan graffiti or a joke!Facsimile of Sonnet dedication
Notice the weird layout. Notice the period after every word. Who writes 'real' text like this? (update -- I later did see one other document like this, a Roman Latin document.) These are (or could be) clues that this is a cryptogram, and they hint at how to decode it. Rollett writes that a well known Shakespearean scholar, John Leslie Hotson, came to the this conclusion in his 1964 book (Mr. W.H.), but he was unable to solve the cryptogram. But Dr. John M. Rollett, after many years thinking about it on and off, (spectacularly) solved the cryptogram(s), wrote it up and published in 1997.
. .
.
(left)
Sonnets dedication
(right) Sonnet's (odd) cover
Facsimile of the dedication published with Shakespeare's
Sonnets in 1609
Notice the weird period ('.') after every word.
Notice the inverted triangle line format: 6 lines,
2 lines, 4 lines
6,2,4 read pattern --- 'These sonnets
all by ever (e ver) [the forth]'
(source Google books)
Until spring of 2011 I had heard only of one possible Shakespearean document with a hidden message, the funerary monument poem, the work of David Roper. But from a draft overview paper by Albert Burgstahler ('Verifying Shakespeare's de Vere Authorship' by Albert Albert Burgstahler, PhD, professor emeritus of chemistry Univ of Kansas, prepared for an upcoming joint Shakespeare Fellowship and Shakespeare Oxford Society meeting in Washington DC, Oct 13-16, 2011) I learned about the sonnet dedication (double) cryptogram, the work of Dr. John M. Rollett in the late 90's.
Dr. Burgstahler is an Oxfordian and his upcoming paper focuses on hidden texts that point to de Vere as the author. Curiously, Rollett, who had been an Oxfordian, is no longer. In the online 'Declaration of Reasonable Doubt' (& here) petition he states he currently has no favored candidate for Shakespeare. I also have no favored candidate, but my interest is not in the content of the hidden texts, but on their mathematical strength. My aim in this little essay is to lay out the case, based on Rollett's and Roper's work, that one (or two) Shakespeare related documents really are cryptograms, and that these cryptograms have been solved revealing relevant and interesting text.
Rollett's
sonnet dedication paper (1999)
John M. Rollett's
original paper on the sonnet dedication was published in 1997 in Elizabethan
Review. I have not been able to find it online, but Dr. Burgstahler kindly
sent me a scan of it, so I have read it. Later I found online a slightly
later paper by Rollett covering the same ground published in the journal
The Oxfordian, Vol II, 1999 (link below). This later paper was prepared
for several talks he gave in 1998. Rollett's decoding of the sonnet
dedication is a fantastic piece of work and his (16 page) paper below is
beautifully written, a classic. It deserves to be better known and I have
some ideas for making it better known.
http://www.shakespeare-oxford.com/wp-content/oxfordian/to-99-rollet-dedication.pdf
Three texts
in dedication
Rollett discovered
three
separate hidden text (names and phrase) in the 144 word sonnet dedication:
1) 6-2-4 word code
THESE SONNETS ALL BY E VER
2) At x15 equidistant spacing the name 'Henry' is spelled out
3) At x18 equidistant spacing the name 'Wriothesley' is spelled out. Rollett sees the name spelled in three fragments, however they are not in the correct order and to pull out 'ioth' he must read up, whereas the others are read down. While I agree it's impressive, it's messiness makes it (on the surface) a little suspect, but mathematically it does stand up. As shown by my mark up near the beginning of this essay, I show another way, not mentioned by Rollett, that 'Wriothesley' can be read out at x18.
Wr esley ioth (Rollett)
Wr io th esley (Fulton)
My reading of x18
Prior to finding
Rollett's paper I had written out the dedication at x18, because I had
read in Burgstahler's draft paper that it contained the name 'Wriothesley'.
What I saw (and prefer) is 'Wriothesley' spelled out in four fragments.
This may not look quite so impressive as Rollett's three fragments, because
the moderately difficult to form four letter fragment 'ioth' has been replaced
by two easy to form two letter fragment 'io' 'th', but much of the statistical
rigor is recovered because the (four) fragments are in order. When the
odds are calculated out, it is exceeding unlikely to have occurred by chance
(less than a million to 1), and I think it is cleaner than Rollett's three
fragment version for two reasons:
1) Order is correct
The four fragments come out in the right order to spell 'Wriothesley'. In contrast Rollett is forced to reverse the order of his 2nd and 3rd fragments to make it spell 'Wriothesley'.2) Read only down
The four fragments are all read down. In contrast Rollett is forced to read both up and down ('wr' and 'esley' are read down, and 'ioth' is read up). The Shakespeare monument poem decode is done only reading down. The only (slight) bending of the downward read 'rule', is that the 'io' fragment spans two columns ('i' is on the bottom row and 'o' is at the top of the next row). I see this as perfectly allowable. (For more on this see Appendix 'Equidistant vs grid decoding')

Rollett's x18 reading
I also see
Rollett's four letter up fragment 'ioth', and I outlined it above
in ink (11th column). Rollett in his paper uses this up and misplaced
four letter 'ioth' fragment to provided the middle letters of the name,
but I prefer to use the two letter fragments 'io' and 'th' (marked in yellow),
both of which are correctly placed and are read downward (like 'wr' and
'esley').
I don't use Rollett's 'ioth' fragment in my odds calculation, but I agree it is striking (even if 'misplaced' and read the 'wrong way') because it is long (four letters) and relevant. I consider it a compounding factor.
So is reading up and down a stretch or just wrong? That's not for me to say, maybe the encoder intended a longish fragment to be read 'up'. Who knows? My point is that you don't need the upward 'ioth', because two downward fragments 'io' and 'th' are there located just where they should be, in order between 'Wr' and ''esley'! I find this impressive. The loss of some statistical strength from breaking up a four letter fragment 'ioth' is partially recovered by four fragments coming out in order.
x18 equidistant decoding
The same type
of equidistant decoding used with the Shakespeare monument poem can be
applied to the Sonnet dedication. Here the equidistant spacing I want to
examine is x18 (reading every 18th letter). An easy way to do equidistant
decodes is to use graph paper. For a x18 decode we just write out the 144
letters of the dedication (sans punctuation and expanding any compound
letters) in rows of 18, then any words or names that exist in the original
text at x18 spacing can easily be read off the graph vertically. No computer
needed, it takes just a few minutes by hand.
Estimate of the
odds
The result of a
simple x18 (equidistant) decode yields the long name 'Wriothesley'. Clearly
'Wriothesley' is relevant (to the Sonnets) as Henry Wriothesley is one
of the leading candidates to be the 'W.H' mentioned in the dedication,
the 'begetter' of the of the sonnets. This 11 character name appears in
four isolated fragments, one of which is five characters long, and all
arranged in the correct order, as shown below:
WR IO TH ESLEY
There is only one way to spell this name (see Appendix), so that means we can calculate the odds of 'wriothesley' appearing by chance in the four fragment form seen above. There is only one 'y' in the dedication (see table below), so we can work forward from the rear 'y' multiplying out the odds as each letter is included. And the letter frequencies are easily found just by counting how often each letter occurs in the dedication.
Letter
frequency in sonnet dedication text
First step in calculating
the odds is to count the frequency of occurrence of the name letters in
the dedication text. 'w' occurs four times in the 144 characters that make
up the dedication text, so the odds 'w' will appear in a specific
location on the graph is the ratio of the numbers of 'w's to the number
of unoccupied letter blocks on the graph. For example, [4/144, or 4/143,
or 4/142, etc], which is approximately 1/36 or (36 to 1).
|
|
in 144 letters of Sonnet dedication |
letter freq |
English letter freq |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Is
the long name Rollett found in an 18x8 grid of the dedication real?
Rollett found
an 11 character name 'wriothesley', one of the two leading candidates to
be 'W. H' of the dedication text, turns up at x18 spacing. This name uses
7.6% [= 11/144] of the available characters and is built from an unlikely
five letter fragment with shorter fragments all in order. But what is the
probability that any long relevant name (or phrase) will appear
at any equidistant spacing. Below I estimate the odds of the long
name found at x18 spacing at about 10 million to one, and any long
name at any spacing maybe 1,000 times more likely, giving us odds
of 10,000 to 1.
One five letter
fragment
Even before
we work out the details we can make a quick estimate of what we are likely
to find. It's easy to guess that the odds of the specific five letter fragment
'esley' are going to be pretty low, after all I worked ten cases in the
monument poem of 220 characters and not a single five letter word showed
up. Below is the calculation with the result the odds are about one in
15,000. The odds of the five letter fragment 'esley' is figured as follows.
It's easiest to start at the end because, there is only one 'y' in the text. So we locate the one 'y' on the graph. This letter has a probability of unity. To spell 'wriothesley' the letter preceding our single 'y' on the graph must be an 'e'. We can see from the table above that 22 of the 144 dedication letters are 'e'. With 'y' removed there are 143 letters remaining, so the odds the letter preceding 'y' is an 'e' is (22/143), about 15%. So multiplying out for the four characters that must precede 'y' in order, we get the odds for the five character fragment 'esley'
'esley' (21/140) x (10/141) x (6/142) x (22/143) x 1 = 1/14,460
Three two
letter fragments
A back of
the envelope calculation shows that the two letter combinations 'wr', 'io'
and 'th' are quite likely to occur, especially 'io' and 'th', because all
four of these letters are common. Here's how to estimate the probability
of 'wr': Find an 'r' and ask what is the probability that the preceding
character is 'w'. That's easy, there are only four 'w's in the dedication
text, so the probability of a 'w is [144/4) = 36 to 1. But this is not
the answer. There are 9 'r's so to a first approximation this reduces the
'w' odds of 36 by 9, giving us odds of 'wr' as [36/9] = 4 to 1. This is
an 'OR' probability calculation and below is the exact calculation.
'wr' [1 - {(144 - 4)/144}^9] = [1 - {(144 - 9)/144}^4] = 0.22 (or 4.4 to 1)
Above shows our back of the envelope calculation of 4 to 1 odds for 'wr' was pretty good, as the exact answer is 4.4 to 1. The back of the envelope method gets less accurate for 'io' and 'th' predicting their odds as close to one. The exact calculations are (in same manner as above)
'io' [1 - {(144 - 14)/144}^8] = [1 - {(144 - 8)/144}^14] = 0.55 (or 1.8 to 1)
'th' [1 - {(144 - 17)/144}^8] = [1 - {(144 - 8)/144}^17] = 0.63 (or 1.6 to 1)
We multiple the above three for the odds three two letter fragments 'wr', 'io', and 'th' appear (here in any order)
1/[4.4 x 1.8 x 1.6] = 1/12.7 (or 12.7 to 1)
Four
fragments in correct order
Finally we
need to figure the odds that the four fragments come out in order. To simplify
the calculation I am going to assume there is only one of each fragment,
not quite right, but close so we won't be far off in out final estimate.
With our simplifying assumption the order calculation is very simple.
The odds of any specific fragment of four (here 'wr') being first is 4 to 1. Odds of a specific fragment of remaining three (here 'io') being next is 3 to 1, the odds of the two remaining fragments being in order is 2 to 1. Multiplying out the odds that the four name fragments line up correctly to spell ['wr io th esley'] we get
1/[4 x 3 x 2] = 1/24 (or 24 to 1)
When I checked, I found two 'th' on the x18 graph, so there is a minor correction to above. It is a little too high, 2 really is 1.5, so 24 becomes 18. In the big scheme of things it makes no difference.
x18 result
The final
result is the odds of the five letter fragment 'esley' [15,000 to 1] times
the odds of the three two letter fragments 'wr', 'io', and 'th' [12.7 to
1] times the odds the four fragments are in the right order [24 to 1].
Since all these conditions must be met we multiply the three odds to find
the odds of 'wriothesley' appearing at x18 spacing.
14,000 x 12.7 x 18 = 3 million to 1 (approx)
But this is not the final answer.
Reduction
#1 -- multiple spacings
The above
estimate of 3 million to 1 (approx) is for 'wriothesley' appears at one
spacing (x18). But if there is nothing strongly special about x18
spacing, then we need to reduce this by an estimate of the number of reasonable
graphs that could be drawn. With a 144 characters and min of 5 char per
row or column we get x5 to x29, or roughly 24 possible graphs. So reducing
3 million by 24, we get an estimate of the odds of 125,000 to 1 for 'wriothesley'
appearing on any possible graph (i.e. at any equidistant spacing).
Reduction
#2 -- other fragment combinations
(pending)
Reduction
#3 -- other relevant words
But why limit
ourselves only to ['wr' 'io' 'th' 'esley']? There are other relevant names
that might have shown up. What is obviously striking about what was
found is that it includes a long five letter fragment with very low odds
(14,000 to 1) just for this fragment. Obviously the probability depends
strongly on the length of the longest fragment of a name or phrase.
'Vere'
For a short name like 'vere', the probability, that it might occur by chance intuitively is pretty high. In fact it is. There are five 'v's in the dedication, so starting at the beginning 'v' and (roughly) correcting for the five 'v's
To accommodate 32 possible spacing we divide by 32, giving us [135/32 = 4.2] or about 4 to 1. In other words the probability of a 'vere' popping out if we look at 32 different spacings we can estimate to about 4 to 1, in other words it has barely any statistical significance.So what reduction should be applied (to our 125,000 to 1 estimate for 'wriothesley') to cover other possible long names or phrases that must also include a five letter fragment. This can only be guessed at, but that are only a few such names and phrases (I would argue) that meet the five character fragment restriction and are also relevant to Shakespeare or the sonnets. I would hip shot this reduction at an order of magnitude (1/10) or so, which rounded down reduces 125,000 to 10,000 to 1.
Summary
Because 'Wriothesley'
can be spelled only one way (well sort of, see Appendix), it is possible
to do a hard calculation of the odds this name will appear as it
does on the x18 chart in the four fragments ['wr' 'io' 'th' 'esley']
ordered correctly. The result of this calculation is about 3 million to
1. Knocking down our 3 million to 1 odds for 'wriothesley' at x18
to accommodate a wide range of spacing gives us [3 mil/24] = 125,000. And
reducing 125,000 by an order of magnitude or so to allow for the possibility
of other long relevant names or phrases (with a five character fragment)
gives us 10,000 to 1. Since this is partly calculated and partly estimated,
I would call it an engineering estimate.
3 mil/[24 (other spacings) x 12.5 (other names)] = 1/10,000 (or 10,000 to 1)
In other words for ''wriothesley' at x18 spacing, where we have hard numbers (based on counting), we get 3 mil to 1 odds. We extrapolate to a wider search range of any equidistant spacing by dividing by 24 (approx). We further extrapolate to include a range of relevant long names or phrases, but requiring them to include a five character fragment, by dividing again by roughly 10. These two extrapolations reduce the 3 million to 1 odds by a factor of 300 giving us a final estimate of a chance occurrence of 10,000 to 1.
I am happy with 10,000 to 1. I would call this definitely statistically significant.
Note, one reason the odds of 'Henry Wriothesley' come out so high is that the five letter string of the first name ('henry') and in the last name ('esley') each include the letter 'y', and there is only a single 'y' in the text of the dedication. For perspective, see the calculation of the word 'write' below, which is a word with two vowels and four of its least common consonant ('w').Statistically significance greatly strengthened by another hidden text
'Henry' at x15 spacing
At x15 equidistant
spacing in the dedication Rollett found the five letter name 'Henry', and
guess what, this is Wriothesley's first name! Meaningful five letter combinations
are quite rare. Rollett found only a handful at the wide range of spacings
he looked at. I found no five letter words in ten spacings of the monument
text (below) I looked at. Below from letter counts in the dedication I
show the probability of this five letter name appearing at this particular
spacing (x15) is about 23,000 to 1. Diving this by 24 other possible spacings
gives us the probability of 'Henry' appearing at any spacing to
be (in round numbers) 1,000 to 1. Rollett in his 1999 Oxfordian paper has
the same number (1000 to 1) for 'Henry' at all spacings.

my x15 graph of dedication to Shakespeare's sonnets
For perspective --- Calculating the odds of another
five letter word ('write')
For
perspective here is the calculation of the odds of a different five letter
word, 'write'. The expectation is that 'write' will be more likely then
'henry' for two reasons. One, it has two vowels (vs one for henry) and
vowels are two or three times more common. Two, its least likely consonant,
'w', occurs four times in the text, whereas there is only 'y' in the text.
The procedure is find a 'w' (unity) then multiply by the odds for the following
four letters 'r i t e', finally to account for the four 'w's we multiply
by four since we can do this four times. (This calculation is not exactly
rigerous, but close enough)
Odds of 'w r i t e' (in a specific grid) = 4 x [ (1) x (9/143) x (14/142) x (17/141) x (22/140)] = 4/8,500 = 1/2,100
In round numbers
the odds of 'write' not popping up in 24 grids of the dedication
is about [100 to 1], or about ten times higher than the [1,000 to
1] odds of 'henry'. My memory is that Rollett in his Oxfordian paper makes
an offhand comment that the odds of pretty much any five letter word is
about the same as 'henry' or [1,000 to 1]. This little example here shows
that's probably wrong. Compared to other five letter words (or names) 'Henry'
is quite unlikely since it has a consonant ('y') that occurs only
occurs in the text, and it has only one vowel ('e').
------------------------------------
This link (below) is a paper by William Ray discussing
Rollett's work and his views on Oxford.
http://www.wjray.net/shakespeare_papers/Rollett_In_Reverse.pdf
=======================================================================================
Shakespeare is buried in the Holy Trinity church in his home town, Stratford-upon-Avon. High up on the wall of the church is a monument to him that consists of large bust with a plaque below containing eight lines of text: two lines of Latin and a six line, 220 letter English poem. There is mention of a Shakespeare monument in the introduction to the first folio, "thy Stratford moniment" usually taken to mean this monument in Trinity church, which places its time of construction sometime between 1616 (Shakespeare's death) and 1623 (first folio).
Is the
stone engraving original?
The working assumption
of those doing the decoding of the funerary monument poem is that the poem
we see today is exactly the same in wording and spelling as when
it was installed. To what extent the monument has been reworked in its
nearly 400 years is not fully known. With equidistant decoding even a minor
change in spelling of one word can easily damage or destroy a (supposed)
hidden message, so the value of the funerary decoding hinges on the poem
text being unchanged. Hence the history of the important and I spent a
lot of time (too much time!) researching it.
I eventually tracked down four early versions of the poem: 1631, 1656, 1721, 1825 (see Appendix for details). The first recorded version of the poem (1631) is from a notebook written only a few years after the monument went up. The last from a 26 page booklet describing Trinity church published in 1825. The wordings and spellings of the four poems are all slightlydifferent from each other and from the current monument! It's easy to show that of these four versions only the 1825 version supported the claimed hidden message. (I also have an Appendix with pictures of the bust from different times.)
So is this the deathnell of the funerary monument decoding? I don't think so. The fact that these four versions are all slightly different from each other, while at the same time being quite close to the current monument text, argues that more likely than not the spelling and wording differences originated with the observers, that the text we see today on the monument is the same as the original. A confirming fact is that the text recorded in 1631 is very close to the text on the current monument.
Nevertheless, risk remainsThe claim
There is an inherent problem with hidden messages that depend critically on details of spelling and abbreviations. As the cryptographers Friedman pointed out in the case of the Bacon cipher, the instructions to the printer or engraver for text containing such a hidden message must be don't change anything, copy my manuscript exactly. At least with a printed document, even if later editors fiddle with the text (as they often do!), copies of the first edition remain, so the message is not lost. But what about an engraved stone tablet?What if in four hundred years the engraved stone tablet of the Shakespeare monument got worn or damaged (cracked, water damage, who knows). This is the monument to Shakespeare, what the church is famous for, of course they are going to repair it.
Now here is the problem. The instructions to the original engraver to not change anything are of course long lost. A new engraver's view would likely be that if he needs to add or remove a contraction to make a line fit that is his business. After all the original engraving is full of combined letters (eq of typographic ligatures) and abbreviated words too (Ys and Yt). Surely it's the words and layout that are important. Or suppose he changes (modernizes) the spelling of a word or two, what's the difference? That was clearly the view of those who recorded the poem i 1631, 1656 and 1721. Suppose by mistake he engraves 'monument' (maybe his usual spelling) instead of 'monvment', what is he supposed to do start over? If he doesn't, 'Vere' is gone from the message!
He has decoded it with x34 equidistant spacing. This is easily done by writing out the poem on graph paper (34 letters to a line) and looking for words vertically. The additional claim is made that there are two hints that x34 spacing is the decoding key. One, there is only one line on the plaque that is indented, and it has 34 characters. (Well, it does if the compound character 'ae' is treated as one character not two! I address this issue in an Appendix.) Two, Edward de Vere being the 17th Earl of Oxford points to 17 or (possibly) 34 as a possible key, and this is confirmed, so think the Oxfordians, when 'Vere' pops out with x34 decoding.
Here a graphic image of the text on the engraved stone below the funerary monument bust. (See an Appendix for a lot of pictures of the monument that confirm this.)

(source --- http://davidroper.eu/Cryptology%2021.10.pdf)
Reduced message
A straightforward
x34 decoding, which I prefer to Roper's all too flexible decoding, gives
what I call a reduced 'message' (below).
HIM SO TEST, HE I VOW IS E VERE DE
This (raw) hidden 'message' in the 220 letter monument poem at x34 spacing is a quasi-grammatical 'sentence' that is clearly relevant to the Shakespeare authorship debate. It is obtained by reading vertically downward with no rearrangement of the words. Here's a scan of my x34 decode with the (above) message words marked in yellow.
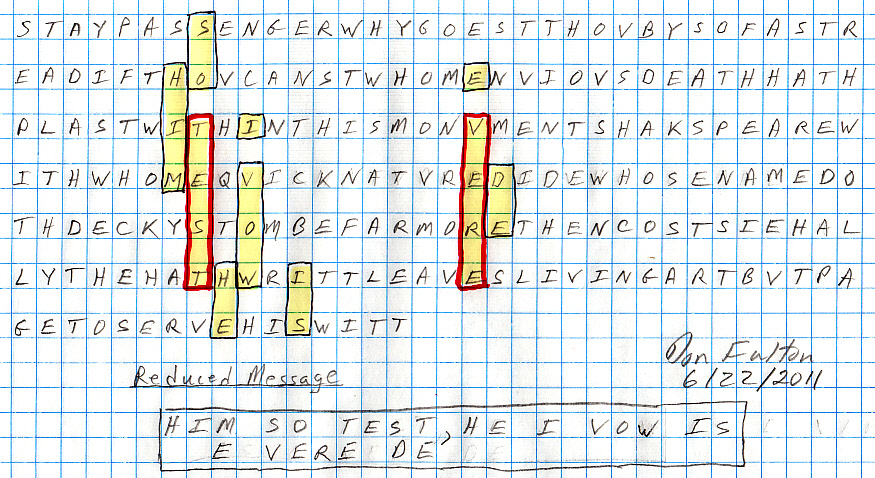
scan of my x34 equidistant spacing decode of Shakespeare's
funerary monument poem.
Marked (in yel) is the 'reduced' (possible) hidden
message that I see (as opposed to a longer, more detailed message that
David Roper sees)
Roper gets a much longer and even more grammatical sentence (below), but I don't like how he plays fast and loose with equidistant decoding rules to get it.
"So test him, I vow he is E. De Vere as he, Shakespeare name, B.I." (B.I. is taken as Ben Jonson's initials)
For example, to get 'Shakespeare' into the message Roper changes to reading horizontal, then he sort of glues it in with 'as' and 'he', but I see this as a cheat because not only is it ad hoc, but a horizontal word is always there. To get Ben Jonson's 'signature' ('B. I.'), which the Oxfordians (apparently) see as critical, he resorts to reversing the 'I. B.' found on the right side. I am not saying he is wrong, just that I think simpler is better, and the reduced message is still impressive.
'Vere' and 'test' with clusters
The case for
trial 34 strengthens, says Roper, when a 2nd four letter word, 'test' can
be woven in with 'vere'. It strengthens more when two and three letter
words adjacent to these two four letter words can be woven in
{'him', 'so', 'test'} {'E', 'Vere', 'de'}
Roper calls these adjacent word groups clusters, and they do look unlikely.
The case for trial 34 is again strengthen when it is found that between these two clusters relevant shorter (fill) words can be woven in ['he', 'vow', 'is'], and we can add in the common 'i' too that precedes 'vow', giving what can be read as a simple, fairly grammatical message below: (Note, use of 'vow' here is a little suspect, since Shakespeare himself in his introduction to an early poem of his spells this word 'vowe')
{'him', 'so', 'test'} ['he', 'i', 'vow', 'is'] {'E', 'Vere', 'de'}
There is another way to group the above words, which I did not see at first. Three of the four fill words ['he', 'i', 'vow'] are in fact adjacent to the first cluster and can be grouped with it. ( 'h' of 'he' is to the right of the last 't' in 'test' and to the right ot 't' is 'w' in 'i, vow'.) With this grouping the first cluster is not as compact, but still since all the words are in successive columns and partly adjacent to each other, it is a cluster, if a somewhat extended and dangly one. With some of the fill words regrouped and attached to the first cluster it's the same message, but it gives at least the appearance of it being less likely a chance occurrence
{'him', 'so', 'test', 'he', 'i', 'vow'} ['is'] {'E', 'Vere', 'de'}
Critical
look at Shakespeare funerary monument poem
At first blush
this all seems pretty convincing, but let's take a critical look. Does
it really contain a cryptogram? Is above really the solution? Let's do
some math.
Is the 'v' in 'monvment' really a 'u'?
There is a
weakness underlying the Stratford monument poem cryptogram. Is the 'v'
in 'monvment' really a 'u'? I think the answer is yes. There is a printing/engraving
convention that in headers and titles written in capitals a 'V's
is used in place of a 'U'. (This swap can be seen in engravings on the
concises of many buildings even today.) Shakespeare always spelled
in his text the word monument as 'monument', never 'monvment'. The capital
'U' to 'V' swich can be seen in his work in some titles and headers, for
example, the title page of his first published poem is 'VENVE AND ADONIS'.
Only after studying spelling conventions of Shakespeare with respect to u,v, did I realize that the 'V's found in the monument poem are really 'U's. Shakespeare's spelling across all of his works, poems, sonnets and First Folio plays, is remarkable consistent. As I describe below in detail, 'v' is found only at the beginning of words and 'u' only inside words, but there is an exception. The exception seen in headers and titles that are printed in capitals is that what an inside 'u' is printed as 'V'. For example, a search of Shakespeare works finds many instances of 'monument' and none of 'monvment'. But if 'monument' were to be printer (here engraved) as a title or heading and in capitals, the printing convention is to switch the inside 'u' to 'V'. And this is what it appears has been done in the monument poem.
The 'v' in 'Vere' comes from the 'v' in 'MONVMENT', but the spelling patterns of Shakespeare, confirmed by searches of his works in original spelling, show clearly that when used in text the spelling is always 'monument'. In other words the only reason there is a 'V' in the critical spot on the engraving to form 'Vere' is that it is a printing/engraving convention with capitals to show a 'V' instead of 'U'. It's really a word 'u' that by a printing/engraving convention with capitals comes out as a 'U'.
Early versions of the poem
First problem, not
mentioned by Roper online (I don't know if his books address this issue
as I am not willing to spend $50 to buy each of them), is that the three
early published version of the funerary poem (1631, 1656, 1721) are just
different enough from the current plaque that it kills the hidden
message. In the message the 'v' in 'Vere' comes from the 'v' in 'monvment',
but in all three early versions you find the spelling is 'monument'. Bye,
bye 'Vere'!
Is this fatal? Well, probably not. After researching this in depth (see Appendixes) , I think it is more likely than not that the observers were sloppy in reading or recording the poem and that the text we see today is the original. However, it must be noted that the early versions of the poem with alternate spellings (and wordings) do introduce some measure of doubt about the claimed crytogram hidden message really comes from 400 years ago.
Math
And what can
the math tell us? For starters one number that pops out (see below)
that puts some perspective on Roper's finding is that the odds of
['E. Vere de' or 'E. de Vere'] arising by chance on some grid is
10%.
Odds of 'Vere'
The key word in
the message, certainly to Oxfordians, and one of the two 4 letter words
in the message is 'vere'. After doing a letter count of the poem [11 or
5% of letters are 'v', 25 or 11.3% are 'e', and 9 or 4.09% are 'r']),
the odds of 'vere' arising by chance are easily calculated. (I do the calculation
below.) The result for it arising (by chance) on x34 grid is 0.57% or 1
part in 174. OK, that seems moderately strong, but if we ask what is the
probability that 'vere' will appear on any grid, say on any of 35 possible
grids, then it is 35 times more likely, or 1 part in 5, or 20%.
Wow, 20%. From this perspective finding 'vere' with equidistant decoding (at some spacing) does not look all that surprising. And while there are hints x34 might be special, it must be remembered that these arguments are only hints and were made after the (so-called) message was found at x34.
Pushing the calculationRaw look at x34
This calculation can be pushed further. So what are the odds of 'E. de Vere' or 'E. Vere de' (as it is in the raw message) appearing by chance on some (not necessarily x34) grid? Ans: wow 10%. There are 'e's scattered all over every grid, so the odds of finding a preceeding 'e' is virtually unity. The odds of 'de' appearing on a particular grid are .50, so the odds of 'e', 'de' and 'vere' appearing on the same grid are .10 or (1 part in 10)We can go still further and ask what is the probability that all the shorter words of the (reduced) message appear on the same grid with 'Vere'. Below is the calculation for 'vere' with all the words of the reduced message except 'test', 'vow', 'him'. Ans: 5% (approximately).
'e' 'de' 'vere' 'he' 'so' 'is' 'i'
1 x .50 x .20 x .886 x .71 x .71 x 1 = .0447 or (1 part in 22)The odds for 'Vere' plus 6 of the words of the reduced message comes out to be 4.47% or 1 part in 22. No mathematical rigor here. What mathematical strength the funerary message has is carried by the minor words: 'test', 'vow', and 'him', not all that reassuring.

x34 spacing (raw)
Note, the words of the 'message' are pretty much lost
in the clutter
The odds of two letter words, like 'so', 'he', or 'is', arising by chance on every grid is very high (odds greater than 75%), so I didn't mark them. [Roper's claim that a two letter fragment 'wr' had odd of a 1,000 to 1 in an equidistant decoding of the sonnet dedication is total nonsense.]
Final odds
Since the (proposed)
funerary poem cryptogram is a phase, no simple calculation of the final
odds are possible. Below I take as stab at estimating it, getting a wide
range 16 to 1,600. (The odds would be 35 times higher if restricted to
x34.) This is moderate to very little mathematical rigor.
Bottom line the nature of the funerary poem only allows for a limited mathematical odds calculation. It does, however, remain interesting with hints that it is moderately unlikely to have arisen by chance, but that's as far as the math can take us. Certainly it doesn't have the mathematical rigor of the sonnet dedication cryptogram, where the solution is a long name, not a phrase.
I do ten trials --- So what's the result?
Well
in the ten trials no five or more letter words were found and relatively
few four letter words. In six of ten trials the longest word has three
letters. In the other four trials six four letter words were found: hale,
tide, stem, shim, test, Vere. Three of these ['shim', 'test', 'Vere'] come
from trial 34, while ['hale', 'tide', or 'stem'] each arise in a different
trial. The (after the fact) key word is, of course, is the (proper) name
'Vere', father-in-law of one of the dedicatees of the first folio, and
in the 20th century considered as a major candidate to have written some
(or all) of Shakespeare's plays and poems.
Calculating
the probability of key words
Calculating
the odds a name will appear by chance is straight forward, but calculating
the odds of a phrase is no so easy. While it may be hard (or impossible?)
to calculate the probability of a phrase being relevant and grammatical,
at least the odds of its key words can be calculated. The procedure is
the same as with the sonnet dedication name. First count the count to find
the letter frequencies in the 220 letter funerary monument poem. Here they
are with a comparison to general (modern) English usage.
|
|
in 220 letters of funerary poem |
letter freq |
English letter freq |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Notice the big disparity between the funerary text and modern english text is the letter 'v'. It occurs x5 times more frequently in the engraved stone funerary poem (5% vs 1%). This is partly because where there would be a 'u' in modern english, like in 'quick, nature and monument', there is a 'v' in the funerary text.
Dugdale/Hollar 1656 versionDoing the word calculations --- Vere, test, vow, him
When Dugdale records the monument and its poem for his 1656 book many of the 'v' are gone. He writes 'quick, nature and monument' not 'qvick, natvre and monvment'. This is important to the x34 Roper message because the 'V' for 'Vere' comes from 'monvment' and the 'v' for 'vow' comes from 'qvick'.With the 1656 Dugdale version of the poem (the original version?) the 'v's for 'Vere' and 'vow' are missing, there is no hidden message!
V
e
r
e
11 x [ (1) x .113 x
.0409 x .113] = .00574 or (1 chance
in 174)
t
e
s
t
27 x [ (1) x .113 x
.0864 x .1227] = .0323 or (1 chance
in 31)
v
o
w
11 x [ (1) x .0636 x .0364]
= .0255 or (1 chance in 39)
h
i
m
7 x [ .0818 x .0636 x (1)] =
.0364 or (1 chance in 27)
Two letter words
Two letter
words contribute only a little to the odds. Two letter word of common letters,
like 'is', 'so' 'he', contribute almost nothing. The odds of 'is' and 'so'
(calculated correctly as inverse of it not appearing) are .71, that is,
there is almost a 3 out of 4 chance of either of them appearing in any
grid, and the odds of 'he' is still higher are .88! Sure enough when I
looked at a few of my trial runs I quickly spotted two occurrences of 'is'.
The odds of 'de' is 0.50 or 50%.
Two letter word odds calculationWhat do these numbers mean?
Odds calculations for two letter fragments tend to come out greater than unity if done approximately, so they must be done more exactly. This means an OR calculation or (easier) the inverse of an AND calculation that the fragment will not appear.The calculation for 'he' using the letter count from the table above (18 h, 25 e) is done this way. For each 'h' on a grid the odds that the next letter (read vertically downward) is not an 'e' is [(220-25)/220 = .8864]. There are 18 h's on each grid, so for 'he' to never appear on a specific grid, 'h' must not be followed by 'e' 18 times, which means taking the 18th power of .8864 [(.8864)^18 = .114]. Subtracting this result from one gives the odds that 'he' will appear one (or more) times in a specific grid [1 - .114 = .886] or 88.6%.
In other words the odds are almost 9 out of 10 the the word 'he' will appear on each and every grid of funerary monument poem, and the odds for 'so' and 'is' are almost as high. Their location may contribute to an odds calculation, but their existence contributes almost nothing.
1 part in [174 x 31 x 39 x 27] or 1 part in 5.6 million
OK, a big number, and it is a hard number directly calculable from the letter count probabilities, but what does it mean? We need to do some dividing. The argument that x34 grid is 'special' is made after the 'message' had been found at x34 and is thus suspect. We can find the probabilities for these four particular words on any grid by dividing our calculated 5.6 million for one grid by (about) 35 for all possible grids, and we get 160,000. This too is a hard number, but we are not done, and now things get a lot more squishy.
Word order
Having words appear
in a specific (grammatical) order can contribute a one or two orders of
magnitude (for example: 4 x 3 x 2 = 24 and 5 x 4 x 3 x 2 = 120), but I
would argue the grammatical order should be 'test him' whereas what we
find is 'him ... test', made more palatable by finding the common 'so'
in between, giving 'him so test'. I will grant that the odds of 'so' appearing
in the small gap between 'him ... test' is small (visually we can estimate
it at 2-3%), but still the result is only quasi-grammatical. How many quasi-grammatical
wording are there?
How many different words?
The problem with calculating
the odds of a phrase, as opposed to a name, is trying to guess how many
different words (and what order) would be accepted as constituting a message?
I don't think there is any way to calculate this. All that can be done
is to guess a dividing factor. We just have to guess at a dividing factor.
Bottom line
My hip shot estimate: 100 to
10,000 possible word combinations. It's just a guess. Applying this divider
to 160,000 we get odds for a quasi-grammatical message on any grid of the
funerary poem: 16 to 1,600. The core problem is this. There is no five
letter word/name anchor in the funerary message (though it could be argued
'evere' stands for E. Vere, and this is good for anther factor of 10),
just two four letter words ('vere' and 'test').
The key word for Oxfordians is undoubtedly 'Vere', but a hard calculation shows the odds of 'vere' appearing on any grid is [174 (for x34)/35 possible grids = 5] or 1 part in 5. In other words there is 20% chance of 'Vere' showing up at some grid of the funerary poem with a 1 part in 16 to 1,600 odds that enough other (mostly small) words will surround it to make a quasi-grammatical phase that can be read as a message. Moderately unlikely, but lacking real mathematical rigor.
I recreate the 'rule of 34' analysis of the funerary
monument text
For this 'rule
of 34' decrypting to work the exact text with its original archaic spellings
must be used, this is crucial. A lot of references (supposedly) give the
original spelling, followed by modern spelling, but I see they differ.
I wanted to start with a clear photograph of the funerary monument plaque
that sits under the bust of Shakespeare high up on the church wall. It
took some searching to find what I needed (the Wikipedia photo is unreadable),
but I located a clearly readable photo of the plaque on a Marlowe site
run by Peter Farey (below).

(source -- http://www2.prestel.co.uk/rey/epitaph.htm)
Mounted below bust of Shakespeare at Holy Trinity
Church, Stratford-upon-Avon, Warwickshire,
sometime between 1616 (Shakespeare's death) and 1623
(First Folio)
This source thinks above contains a riddle, but PETER
FAREY's interpretation is that it points to Marlowe!
Comparing the two poem imagesUnfortunately the plaque may have been fixed up, or replaced, when the monument was restored after it was vandalized in the 1970's. It does look awfully clean for a 400 years old plaque! In comparison with old photos Farey sees at least one change in punctuation and the 'C' in 'Canst' (2nd line) now looks like a 'G'. This is disturbing, but the photo is the best reference I had, so it is what I used.With more searching (see appendix) I now agree with Farey about the changes to the 'c' in 'canst'. I located what appears to be an old photo of the monument, a BW photo that shows two finger tips missing, and in this photo 'canst' clearly starts with a 'c'.
---------------------------------------------------------------------------------------------------------------------------------------------
Comparing my chart to David L Roper's (6/2/2011)
I generated
my 34 char chart above entirely independently from Roper's version. I make
no claim to originality as I know I had read his analysis years earlier
and had a vague memory of it, though I did not find currently active links
to his stuff until after I finished.
Below is the link to Roper's 2009 'Cryptology' essay, which contains his analysis of the Shakespeare funerary poem. My chart and his chart are for all practical purposes identical. Facts are facts. In the write out of the poem in a 34 char/line format they are exactly the same. This confirms no fudging and no errors, we both have the poem text from (modern) pictures of the plaque beneath the Shakespeare bust written out as 34 char/line with with spaces and punctuation dropped. We both highlight the key De Vere related 'text' that appears in vertical columns, but in auxiliary text I highlight a couple of words he did not, and vice versa. He has a fairly lengthy commentary on the results.
Roper's cryptographic message arguments
He quotes
a cryptographer who gives guidelines for interpreting if text found by
cryptographic analysis is a real message and not random: Message should
be grammatical, informative, and unique. These seem to me a good standard,
and Roper says the message meets all three criteria. Well, I pretty much
agree, though as to grammatical this is a judgment call, as it is roughly
in the right order, but not strictly so.
His other key point is that the mathematics of a quasi-grammatical, informative message like this coming out randomly are impossibly small. The paper of his I just read does not give the details of his math, but my intuition as an engineer familiar with math is that his argument is probably sound.
Important find
In other words
if this is Roper's discovery, which he says (or implies) it is, then he
has found something very important in the Shakespeare authorship debate.
And he doesn't oversell it, saying only that this message is 'Ben Johnson's
"avowal" that Edward de Vere was Shakespeare'. And I agree with him that
this finding may not be appreciated as its strongest argument is mathematical
and most literary types are unfamiliar with math, and therefore unlikely
to grasp the (likely) strength of the probability argument.
There are quite a few 'little things' that fit with the big picture too. The most obvious being that the spacing on the equidistant code is 34 = 2x17, where de Vere with the 17th Earl of Oxford. Roper also points out that what many critics have puzzled over 'sieh' as a strange spelling (or incorrect) old spelling for 'since' is needed to make the Ben Johnson initials work.
Roper identified 'I,B' in the right corner as standing for Jonson's initials, a signature of the hidden message if you will. But they are reversed initials from how Jonson signed (see below). A 'B,I' does exist in the 34 equidistant rewrite (lower, center) and I marked it red dotted above. (Did Roper not mention the reversal to strengthen his argument? Don't know, but the 'B,I' I found and marked is pretty obvious.)
First Folio poem --- To the Reader
I searched
out a facsimile of the First Folio introduction and located a page with
a poem by Ben Jonson to see how he signed. Here it is and as you can see
he signs 'B. I.' not 'I. B.'.

First folio introductory page (cropped)
Note spelling of 'wit' and 'writ'
Brandeis University who seem to link to Tufts University)
http://www.perseus.tufts.edu/hopper/image?img=1998.04.0002
I have noticed some curious correspondences between this poem and the poem on the funerary monument, like wit/writ. Both were (supposedly) around the same time, and some think both by Ben Jonson. But notice the facsimile spelling of the four key words below is different in the two poems. A strong argument I would think they were not written by the same person.
First Folio 'To the Reader'
Funerary poem
------------------------------
------------------
writ (vvrit)
writt
wit
witt
nature
natvre
Skakespeare
Shakspeare
Of course, I recognize that this argument can be inverted to argue that the alternate spellings in the funerary poem are an indication that it is a cryptogram. However, the extra 't' in 'witt' doesn't made any difference because it is the last word in the funerary poem, except possibly to visually match 'writt'.
Weird spelling of 'Shakspeare' in the poem -- missing
'e'
Shakespeare's
first published works in 1593, the poems Venus and Adonis and Rape of Lucrece,
which he is thought to have helped publish, spells his name 'Shakespeare'
('s' written in a stylized swooping way) (see below). The title page of
the First Folio (see above) in 1623, edited by Shakespeare's acting colleagues
and fellow writer(s) identifies the author of the plays as 'William Shakespeare.'
So major authorized publications of Shakespeare works spanning his working
lifetime and recent death spell his name the same: 'Shakespeare'. Why the
hell then does the funerary poem on his monument in the Trinity Church
spell his name 'Shakspeare'? This is not just an alternate spelling of
some word, this is the name of the man being memorialized.
Robin Williams in her 2006 book 'Sweet Swan of Avon' has addressed the issue of the spelling of Shakespeare's name too. After mentioning the well known fact that all his signatures on legal documents spell his name differently, and none of these spellings is 'Shakspeare', she says in "Yet in all but two printings of every play that beares his name over a 32 year period, the plays were attributed to 'Shakespeare' "(p189). In her notes she identifies the two anomalies as Love's Labor's Lost in 1598 by 'W. 'Shakespere' and King Lear in 1608 by 'William Shak-speare'. I would add that the poems, which Shakespeare supposedly helped publish, also spell his name 'Shakespeare'.The only reason I can think of (aside from encoding a hidden message) is to adjust the length of the line containing the name. The poem fits on a plaque, engraved in stone (or metal), and hence looks and fits best if its lines are fairly even. It looks like the poem was probably composed with this requirement in mind. The poem consists of three pairs of rhyming lines. With double characters expanded the number of characters/line is [220/6 = 36.67]. The letter counts of the lines vary a little from the average, but the typography and spacing are adjusted so the right edge of the poem is pretty well justified, but not fully justified. The 2nd line projects out about compared to the other five lines by about one character.Spell checkBottom line
I did a quick check on William's claim by looking at a bunch of facsimiles title pages (dated prior to first folio) and indeed all that I could find spelled Shakespeare's name in the modern way. The 3rd folio of of 1664 title page has 'Shakespear's', which leaves out the trailing 'e', but this is the possessive form, and of course this is the same portfolio that includes seven new Shakespeare plays, only one of which is now accepted as being by Shakespeare.
So bottom line the (so-called) Shakespeare funerary monument in Trinity church in Stratford on Avon appears to celebrate the writing of some clyde named 'Shakspeare', a name which appears in not a single authorized, or unauthorized, contemporary published work of the author we know as 'Shakespeare'.
The 3rd line has [37 letters characters + 6 spaces], about average for the poem, but its length is shrunk by five merged letter pairs ['th' (3 times), 'me' 'nt']. The 2nd line has [40 letters + 8 spaces] with three merged letter pairs. The 2nd line (loosely speaking) has 7 more characters [3 more letter, 2 more spaces and 2 less merged letters] to fit than the 3rd line, but the typography and spacings of these two lines have been adjusted so that 2nd line comes out only a little longer than the 3rd line, which contains 'Shakspeare'. The typography adjustments can be seen near the ends of the two lines. In the 2nd line 'eath hath plas' containing [12 letters + 2 spaces'] is directly above, and takes up no more length than, 'with whome' containing only [9 letters + 1 space] on the 3rd line. Still even with these adjustments, the 2nd line, is longer than the 3rd line and longer than any other line in the poem.
The key point, as can clearly be seen below, is that there is easily enough space for 3rd line to have expanded by one character, to have allowed 'Shakspeare' to expand to 'Shakespeare', the spelling used in Shakespeare's poems and the first folio. There is a hole, a blank spot, under the 't' of 'plast'. (And if 'whome' at the end of the line had been spelled 'whom' as in the line above, then the available space An 'e' added to 'Shakspeare' would make the 3rd line just about the same length as the 2nd line. It clearly fits with no adjustments. So where is the 'e'?
Did the engraver perhaps not know beforehand that the 3rd line would fit and maybe just left out the 'e' as a precaution? Can't he count? The 3rd line contains about 7 less characters than the 2nd line, it's going to be shorter, it is going to fit.

2nd and 3rd lines of the furnary poem as it appears
on the monument
Why 'Shakpeare'? Where is the missing 'e'?
To be fair I suppose it could be argued that the poem now has a right justification based on couplets. The two lines of the first couplet are slightly longer (by one character) than the four lines of the next two couplets, whose right justification is excellent. And to get the right justification of the last four lines of the poem, the removal of 'e' from Shakespeare in the 3rd line, it could be argued, was required. However, this argument is weakened by the fact that the 1st line looks shorter than the 2nd line, that this couplet is not really right justified. To right justified the first couplet the 1st line would need a fully formed question mark to lengthen it, but pictures only show a rump (or no) question mark at the end of the first line.
Bottom line on missing 'e' in 'Shakspeare'
There
are four possibilities (that I can think of):
1) Alternate spelling of Shakespeare's name (I don't believe it, not consistent
with his major publications
or virtually any printing of his plays, poems, or legal signatures.
2) Local (Stratford) family spelling, or maybe the name on the church records.
(maybe)
3) Done for aesthetics, to right justify the last four lines (2nd and 3rd
couplet pairs). (maybe)
4) Done as part of encoding the hidden '34 equidistant space' message (maybe)
It is certainly true that the presumed message is destroyed if an 'e' is added to 'Shakspeare'. Lost is the strength of the message, both four letter words, 'trust', 'vere', as well as the three letter words 'vow' and 'him' and what Roper reads as Ben Jonson initials, 'I,B'.
In summary while this is an argument in favor of the hidden message it is not a strong argument. It's true the 3rd line could easily be lengthened to accommodate the extra character by shifting the remaining characters right a little. But to do so without adjusting it typography and spacings of the 3rd line would take away a little from the aesthetic view of the text by messing up the right justification of the 2nd and 3rd couplets. I mean this is a poem intended to go on a plaque on a monument!
On the other hand if the 2nd line typography could be adjusted so that with seven extra characters it only extends out by one character, couldn't the same type of adjustment easily be done on the 3rd line? Adjust it's typography and spacing to spell Shakespeare's name correctly and still retain the aesthetic right justification. I don't see why not.
So all in all I take the oddball spelling of Shakespeare's name in the poem ('Shakspeare') as a possible, not so strong, but not too weak (How's that for a hedge!) indication that the poem spellings have been been tweaked to allow it to contain a hidden message. As others have noted, another apparent spelling weirdness in the poem is a repeated word spelled two different ways: 'whom' and whome', but there's a counter argument to saying this is to support the hidden message. 'Whome' is rhymed and visually aligned with 'tombe'.
Old English spelling problem --- Vow vs Vowe
I was talking
about the possible code in the monument text to a friend showing him my
page above. He commented that the spelling of the message should be in
old english, which hadn't occurred to me, but of course is right. This
brings up a problem with the word 'vow' in the message.
While poking around online looking for original sources I came across the dedication to Shakespeare's first published work the poem Venus and Adonis (1993) for which he is credited with writing the dedication, probably because it is thought he worked with the publisher on publishing the poem, and it is signed my him. What makes it interesting in the context of the message is that the dedication contains the word 'vow' as spelled by Shakespeare, but he spells it 'vowe', not 'vow'! Below is a facsimile of the poem's dedication page. It's clear that the spelling of a large number of the words in the dedication are different from modern spelling. 'vowe' occurs in the 6th line ("and vowe to take aduantage of all idle houres").

source -- http://shake-speares-bible.com/2010/04/18/james-shapiro-and-the-notorious-hyphen/
Roger
Stritmatter on this site implies the original is at the Folger Shakespeare
library
Doing some searching I found a complete facsimile copy of Venus and Adonis at the link below, and it does contain the dedication page above (p79). (A reproduction in facsimile of the first edition, 1593, from the Malone collection in the Bodleian library. Google ebooks)
http://books.google.com/books?id=9Go3AAAAIAAJ&printsec=frontcover#v=onepage&q&f=false
Spelling footnote----------------------------------------------
Spelling of 'aduantage' (above) is interesting. Where we would have a 'v' there is a 'u'. On the other hand in the funerary poem where modern spelling would put a 'u' we nearly always (or always) find a 'v'. (I think I remember seeing this in Ben Franklin's writing too more than 150 years later.) It's but a single example, but it hints that maybe since Shakespeare's time 'u' and 'v' have been reversed in English?Yup, in a quick search on a page about Elizabethan spellings I find this, "Couldn't Elizabethans spell properly?" and "Why is there so much confusion with the letters 'u' and 'v' and 'i' and 'j'? (source -- http://www.william-shakespeare.info/william-shakespeare-dictionary-v.htm)
http://davidroper.eu/Cryptology%2021.10.pdf
In his paper Roper references two others working on the code. One is Univ of Kansas professor, Albert Bergstahler. The link Roper gives is dead, but I searched out the professor's page on the Univ of Kansas web site. He is a retired emeritus professor of chemistry, and his page does say he has been working on the Shakespeare authorship problem since he retired (1997). The other (Dr. Bruce J. Spittle, New Zealand) has given a reason why the 2nd Latin line might be indented. It is because it has 34 characters says Spittle and Roper a clue that this is the equidistance code spacing.
However, I counted the char in that line. if you break apart the combined 'AE' into two letters, as the combined 'TH' in the plain text must be broken up, then it contains 35 characters! (update 6/4/11) In an email from Spittle he argues that 'AE' in old english and Latin is really a single character and different from 'TH', which looks to me like a typography thing. This is a technical issue about which I know basically nothing. I have no reason to dispute Spittle's view on this.
Miller's attack
Here is a
link to a recent (2010) 38 page discussion of Roper's cryptographic analysis
of the monument poem titled: 'It there a cypher in Shakespeare's Epitaph
as claimed by David Roper in his book, Proving Shakespeare (2009)?'.
http://www.ericmillerworks.com/images/pdf_files/Shak%20Cultural%20Due%20DiligenceAugust.pdf
Eric Miller (above) here has collected a half dozen or so of early copies of the monument text. They are clearly all the same poem, but in in spelling and word detail they are they all different from each other! Thus they provide no guidance on what the original text detail might have been. But interestingly the last version included in Miller's document (p497 from Life of William Shakespeare by Sir Sidney Lee) is cryptographically identical to the exant monument with one exception that 'sieh' is replaced by 'sith'. Since both have four letters, this only affects one word of the message, the presumed signature of the author 'I,B', which uses the 'i' in sieh.
Miller's main point of attach on Roper is that in none of the early poems does the word 'sieh' occur. Most have 'sith' (one has 'since'). Roper, perhaps unwisely, emphasized the importance of 'sieh' arguing that it was unusual, a weirdness in the plain text if you will, and thus providing a clue that the text had been 'tweaked' to include a message, here needed to provide the 'i' in 'I, B' (Ben Johnson's initials). But this is one brick in a multi-brick ediface, and with it removed most of the message (So Test him, I vow he is E de Vere....) is still intact.
Furthermore neither Roper or Miller seems to have noticed what I have noticed. You can still argue that Ben Johnson initials are in the message, because in the center of the text you can find 'B,I', where 'b' ('tombe') is just above 'is' so the 'i' is shared. And 'BI' matches better then 'IB' how Ben Jonson signed his work in the introduction of the First Folio.
On the absolutely
key point of the probability of the message (even if we remove 'I,B') Miller
says nothing, begging off saying that he doesn't know enough about
cryptography, translation, he doesn't do math.
===========================================================================================================
David
Roper on Rollett's sonnet dedication
I recently
came across a short paper on the by David L. Roper (link below image) on
the sonnet dedication cryptogram. To be kind I can say in his probability
calculations he solved the wrong problem, but my real reaction is Oh
My God (as they say in 'Legally Blond' the musical).
* Roper claims to have extended Rollett's work by finding a new phrase at x19, but it's formed by moving letters around and flying around the grid picking up single letters. It's not a decode, it's just word play. No one should take this seriously.
* For some reason Roper rejects one of Rollett's mathematically strongest finds: five letter name 'Henry', clearly relevant as Wriothesley's first name, on x15 grid.
* Roper's probability calculations are different from Rollett's and totally wrong. Roper includes in his calculations the letter probability for the first letter of a string, but this is incorrect. When calculating if a string can exist anywhere on a grid, the probability of the first letter is unity, because this is where you start. Also Roper doesn't account for the fact that multiple instances of the first letter provide multiple locations where a string might form. And finally he uses the wrong letter statistics, using average English letter statistics instead of letter statistics based on a count of the actual text. These three errors lead Roper to calculate odds that are far too high, and in the case of short strings grossly too high. For example, Roper says the probability of the two letter string 'wr' arising by chance is 1,000 to one, whereas its more like 4 to 1 (or close to 2 to 1 if reading up and down is allowed).
x19 discussion
Look at the
x19 grid below of sonnet dedication. This is the kind of thing in my opinion
that turns people off to claims of hidden text in Shakespearean cryptograms.
A classic example of 'a bridge too far', of seeing 'way too much'. It's
taken from a paper by David Roper on his site (link under image) titled:
SHAKE~SPEARES SONNETS, T(HOMAS) T(HORPE)'S ENIGMATIC
'EPIGRAM'. The paper discusses Rollett's decryption work, and then Roper's
claimed extension of it.

David Roper's x19 sonnet dedication grid
(source -- http://www.dlropershakespearians.com/the_sonnets_epigraph.htm)
What?
Roper reads
out from above, by as he admits, "rearranging these words":
TO VERE, W.S., HIS EPIGRAM. W.S.
Give me a break!
He reads 'ish'
(center top, green) as 'his' by moving letters around, but the classic
is his reading out the word: 'epigram'! 'Epigram', which he uses in the
title of his paper, he gets from: 'pie' (left, green) + 'r' (center, green)
+ 'amg' (left, green). He admits "questions of authenticity" are raised,
but only because it is "split into three parts". But it's much worse than
that. Look at what he had done. To get 'epigram' he flips around letters
of ''pie' (left) making 'epi', then goes far right for 'g', back to center
for 'r', then back far right again for 'am'. This is frankly ridiculous.
If you can flip letters around and jump all over the place for single letters,
this is not decoding, it's just word play.
Roper says, "The first major breakthrough into decoding the meaning behind this text (sonnet dedication) was suggested by Dr. John Rollett", implying that his (claim to) finding a phrase containing 'epigram' at x19 is another breakthrough?
Roper on 'Henry'
Roper mentions
briefly Rollett finding 'wriothesley' at x18, but for some reason rejects
Rollett's finding of 'henry' at x15. He says, "There are no grounds for
concluding that its ('henry') appearance on another grille was the result
of a deliberate act on his (Thorp's) part." But 'henry' is a difficult
five letter name to make from the 144 letters of the dedication, because
there is only one 'y' in the text and only one vowel in the name (1 in
1,000 odds I calculate). So there are 'grounds', mathematical grounds.
I agree with Rollett that having one of the handful of five letter name-words
that pop up (considering all possible grids) be Wriothesley's first name,
Henry, is striking, and the math confirms it very unlikely to occur by
chance.
Roper's odds
calculation
My first thoughts
on seeing Roper give the probability of 'wr' occurring by chance in the
sonnet dedication as 1,000 to 1 was this: Doesn't this guy have any mathematical
intuition? Two letter strings in grids are quite likely to occur by chance.
And how come he doesn't mention, or explain, why his calculated odds differ
so much from Rollett's?
Trying to figure what he did, I tracked down Roper's reference, which he gives as a paper by Beker and Piper included in a well known book on coding by Simon Singh. Below is the relevant page from Singh's book giving the Beker and Piper's letter frequency data. Sure enough if you multiply the numbers from this table for 'w' and 'r', you get [0.023 (w) x 0.06 (r) = 0.00138], which rounds to 1000 to 1, so this must be the source of Roper 'wr' odds.
Where the table above applies
Roper's reference: English letter frequencies in general usage
[.023 (w) x .06 (r) = .00138] or about 1,000 to 1source --- Beker and Piper table from 'The Code Book,
The Science of Secrecy from Ancient Egypt to Quantum Cryptography'
by Simon Singh, 1999
Errors
in Roper's odds calculation
In doing his
'wr' calculation Roper has made a fundamental error, actually three fundamental
errors.
1) Roper has used letter probabilities for general English usage. Here we have a specific text (sonnet dedication), we can just count the occurrence of its letters. The results for 'w' and 'r' are actually pretty close to the general usage statistics above, 'w' is [(4/144) = 0.028] vs 0.023 (table) and 'r' is [(9/144) = 0.063] vs 0.060 (table).Here's another take on itThe question on the table here is what are the odds than a 'wr' (one or more) will appear by chance in a grid of the sonnet dedication text? What are the odds we will find (at least one) 'w' somewhere in a grid? It is unity. We have counted and know there are four 'w's in the dedication text, so it is 100% certain we fill find four 'w's somewhere on each grid. The calculation we want to make is what are the odds that in the specific locations adjacent to 'w's an 'r' might appear by chance.
2) The biggest error Roper makes is that only one letter probability is involved not two. A point Rollett in his 1999 paper makes crystal clear. We are asking what are the odds that adjacent to a 'w' we know is there (unity odds) will be an 'r'? Only the probability of 'r' counts in the calculation associated with each 'w', and there there are multiple occurrences of 'w' that lowers the odds further.
3) Multiple occurrences not accounted for. Another major factor Roper misses is that there are multiple possibilities to form a 'wr' on each grid because there are because there are multiple occurrences of the starting letter 'w'. With four 'w's there are four times more locations where we can have an adjacent 'r'.
Roper quotes odds of 1,000 to 1 for the two letter string 'wr'. This would be the answer if the problem was the following: Point at a random letter in a random text and ask what is the probability it's a 'w' (2.3% from average English usage tables), then what is probability the following letter is an 'r' (6%). Multiply these to get the probability for the two letter string 'wr' (0.14%), which rounded is odds of 1,000 to 1. But the problem at hand differs from this in three significant ways:
1) We have not a random text, but a known text. Letter probabilities are arrived at by counting. Four 'w' and nine 'r' in a text of 144 letters yields letter probabilities of 2.8% for 'w' and 6.3% for 'r'. (For these two letters the results are quite close to general usage statistics, but this would not always be the case in a text so short.)
2) We do not start at a random letter, but at the first 'w'. It must be somewhere on the x18 grid because it is in the text, so the probability of a 'w' is not .023, it is 1. The locations ('r') is now defined as it is adjacent to a 'w', so for 'r' probability we use its count statistics (6.3%).
3) There are multiple instances of 'w', a fact which Roper ignores. With four 'w's' in the text there are four more locations where an adjacent 'r' might pop up to form an 'wr' string, hence (to the first order) the 6.3% probability rises to about 25% for reading only down (approaching 50% for reading up and down). A far cry from Roper's 1,000 to 1 odds.
Or maybe?
It's hard
to understand how Roper doesn't see that the probability assigned to the
first letter of a string on a grid should be unity, especially when Rollett
clearly shows this, or that multiple occurrences of the first letter to
be accounted for. Is Roper really this bad of a mathematician? Or is possible
that Roper understands perfectly well what he is doing and is trying to
deceive the reader with inflated odds?
===========================================================================================================
One
way to spell 'Henry Wriothesley'?
Yikes, it
seems nothing in Shakespeare is ever simple. Nearly every literary reference
spells Southampton's name 'Henry Wriothesley", but looking at some facsimiles
of the dedications of the two Shakepeare poems I noticed these alternate
spellings: 'Henrie', 'Wriotheslie' and 'Wriothesly'. However, the
first editions of the two Shakespeare poems that precede the 1609 sonnet
dedication the spelling of Southampton's name is
Venus and Adonis 1593
Henrie Wriothesley
Rape of Lucrece 1594
Henry Wriothesley
These poems are the first two published works of Shakespeare. Shakespeare is thought to have been involved in their publishing, and these two dedications are signed by Shakespeare. Yet we find that the spelling of the earl to whom the poems are dedicated is spelled differently ('Henry' and 'Henrie') most likely by Shakespeare himself. The conclusion I draw is that either spelling of his first name is acceptable for the Earl of Southampton. Good news is that the spelling of his last name is the same in both dedications.
Below are a few early facsimiles and later editions showing how Henry Wriothesley's name was spelled. Notice the Scottish 1627 edition of Venus and Adonis, though nearly identical in spelling to the 1593 first printing, has changed the spelling of 'Henrie' to 'Henry'. Possibly an indication that 'Henry' is, or has become, the preferred spelling of Wriothesley first name, or certainly that 'Henrie' and 'Henry' are both acceptable spellings.
 .
.
-- Henrie Wriothesley --
Facsimile of the 1593 (first) edition of Venus and
Adonis dedication
("from the unique copy in the Malone collection in
the Bodleian library")
(source Google books)
 .
. 
-- Henry Wriotheslie --
1627 Scottish edition of Venus and Adonis
(source Google books)

-- Henrie Wriothesley --
1901 Venus and Adonis
(source Google books)
 .
. 
-- Henry Wriothesley --
Facsimile of the 1594 (first) edition of Rape of Lucrece
title and dedication
Note the weird, but commonly seen, inverted triangle
shape in the heading of the dedication.
("from the copy in the Malone collection in the Bodleian
library")
(source Google books)

-- Henry Wriothesley --
Rape of Lucrece dedication, 1903 edition
(source Google books)
I read that others have looked at the monument poem at spacings other than x34 and report seeing little of interest, but to form my own judgment about the likelihood of the purported hidden message it was important that I do a bunch of cases myself. I did it manually for ten different spacings (32 to 40, and 17), by writing out the 220 poem letters on graph paper. I then read through (vertically of course) looking for words.
Signal-to-noiseLooking for words is a crude procedure as I know next to nothing of Elizabethan words or spelling, but I tried to be inclusive, for example marking words like 'hale', 'shim' and 'cot', that I suspect may be of more recent vintage. I marked (in yellow) only words with three or more characters in length, ignoring the more likely two and one character words (every 'a' and 'i' in the poem is a potential one character word). This is a little arbitrary, but it's my choice, and I think its a reasonable way to reduce noise, while getting a look at the key (less likely) words. These can then be compared with 34 spacing, which has two relevant 4 letter words ('test' and 'vere').
I am an EE engineer and was trained in the mathematics of noise. Also I did analog circuit design for forty years, so I have some feeling for signal-to-noise ratio. By doing ten cases I hoped to get a feeling for the signal-to-noise, or in other words how much does spacing x34 stand out from the other spacings.What I found was in terms of simple word count, meaning the number of 3 and 4 letter words, the signal-to-noise is fairly low. Spacing 34 does stand above the background, but barely with only a couple of more 4 and 3 letter words than other spacings: two (or three) four letter words vs one for several other spacings and ten 3 letter words vs eight for another spacing. In toto spacing 34 has 12 yellow marking vs 7 and 8 yellow marking for two other spacings. It's higher, but not so high that it really jumps out. (More on this below)
Bullseye on barn door problemThe situation with this hidden deVere poem message (if it is there!) is similar. The content of the message was not specified in advance and then looked for. It was found I gather by David L. Roper. The decoding 'rules' given just happen (surprise!) to be consistent with the message being found, like spaces are excluded, punctuation is excluded, words spanning two columns are excluded, liberal spellings are included ('vow' instead of 'vowe'). All these, while seemly reasonable, have some degree arbitrariness and smell of painting the bullseye on the barn door after the shots have been fired.
The big problem in assessing the likelihood of a hidden message is fooling yourself. It is so easy to select or adjust a target to agree with data already in hand. A classic case of this is first firing bullets at a barn door and then painting a target on the door centered where the hits are concentrated. This problem is also rife in large scale medical studies where unlooked for, often surprising, correlations are found. For a long time these correlations (possible cause and effect) have been had been taken seriously, but more and more doctors are coming to understand the probability of such correlations arising in a large study is quite high. My understanding is that a quality large medical studies must specify in advance what is being examined and what correlations are to be looked for, other correlations that may be visible in the data are now disregarded, because the probability is too high that they are statistical flukes, or noise.
So trying my best to not bias the result, below I treat 34 spacing like all the other spacings. I do not mark out the supposed message on the 34 chart.
So what's the result?
Well
in the ten trials no five or more letter words were found and relatively
few four letter words. In six of ten trials the longest word has three
letters. In the other four trials six four letter words were found: hale,
tide, stem, shim, test, Vere. Three of these ['shim', 'test', 'Vere'] come
from trial 34, while ['hale', 'tide', or 'stem'] each arise in a different
trial. The (after the fact) key word is, of course, is the (proper) name
'Vere', father-in-law of one of the dedicatees of the first folio, and
in the 20th century considered as a major candidate to have written some
(or all) of Shakespeare's plays and poems.
'Vere' and 'test' with clusters
The case for
trial
34 strengthens when a 2nd four letter word, 'test' can be woven in. It
strengthens more when two and three letter words adjacent to these two
four letter words can be woven in
{'him', 'so', 'test'} {'E', 'Vere', 'de'}
Roper calls these adjacent word groupsclusters, and they do look unlikely. Below I do a little cluster math.
The case for trial 34 is again strengthen when it is found that between these two clusters relevant shorter (fill) words can be woven in ['is', 'vow', he'], and we can add in the common 'i' too that precedes 'vow', giving what can be read as a simple, fairly grammatical message below: (Note, use of 'vow' here is a little suspect, since Shakespeare in his introduction to his early poem spells this word 'vowe')
{'him', 'so', 'test'} ['he', 'i', 'vow', 'is'] {'E', 'Vere', 'de'}
There is another way to group the above words, which I did not see at first. Three of the four fill words ['he', 'i', 'vow'] are in fact adjacent to the first cluster and can be grouped with it. ( 'h' of 'he' is to the right of the last 't' in 'test' and to the right ot 't' is 'w' in 'i, vow'.) With this grouping the first cluster is not as compact, but still since all the words are in successive columns and partly adjacent to each other, it is a cluster, if a somewhat extended and dangly one. With some of the fill words regrouped and attached to the first cluster it's the same message, but it gives at least the appearance of it being less likely a chance occurrence
{'him', 'so', 'test', 'he', 'i', 'vow'} ['is']
{'E', 'Vere', 'de'}
or
HIM SO TEST, HE I VOW IS E VERE DE
Reduced message
Above is the
(raw) hidden message I find with spacing 34. The other elaborations of
Roper I find much less convincing. For example his including horizontal
'Shakspeare' as part of the message, and then sort of gluing it in
with 'as' and 'he'. I reject this as falling into the category of likely
to be fooling yourself. The vertical coding rule is being broken, it seems
to me, just because it seems to improve the message. Same with some two
letter combination 'I, 'B', which are considered to be Ben Jonson's initials
written reversed. I reject this too.
scan of my x34 equidistant spacing decode of Shakespeare's
funerary monument poem.
Marked (in yel) is the 'reduced' (possible) hidden
message that I see (as opposed to a longer, more detailed message that
David Roper sees)
2 Letter: At (6th col), So (8th col),
He (9th col), In (14th col), Go (16th col),
In (22nd
col), As (28th col), He (30th col), Am/Me (31st col)
I think of above as a reduced (possible) hidden message in the poem, in contrast with the much longer, and detailed and more grammatical message that Roper manages to pull out of the funerary poem. This reduced message is as far as I want to go personally in identifying a (possible) message in the poem. No bending the rules to include a horizontal 'Shakspeare', no rearrangement of the words to improve the grammar, no signature, or at least what Roper identifies as a signature ('I, B' for Ben Jonson). Still the 'reduced message' does look like a message, is fairly grammatical, fairly compact, and is clearly relevant to the authorship of Shakespeare's literary cannon.
Marie Merkel
After I finished,
I found a 2009 posting (below) by Marie Merkel in a forum on an Oxford
site discussing Roper's book. She like me decided to independently check
Roper, to see what pops up with different spacings, and at x34 she reads
out exactly the same 'hidden' (reduced) message I find, dropping the final
cluster and 'signature', giving it as:
Him so test, he, I vow, is.... (tin) E Vere de (tin, hot)
http://edwardoxenford.org/forum/index.php?action=printpage;topic=29.0
Actually, if I include all the three and four letter words at x34 (the 'noise'), I get quite a few more small words than Merkel:
(pit) (s)Him so test, (t)he I vow, is (tin) E Vere de (tin, hot, set, ham, are)
So what are the odds?
This reminds
me of figuring the odds of life in the galaxy using the Drake equation.
While some numbers in the Drake equation can reasonably be estimated, they
are swamped by others that are nothing but wild guesses. Same here with
the message. We can made a rough estimate the the odds of two four letter
words, the odds that shorter words will cluster with them, but these numbers
are swamped by the odds of the message will be (reasonably) grammatical
and (big one!) relevant either to the text of the poem or the purpose of
the monument. I see no way to put a number on the latter, it can only be
guessed at.
Odds of two four letter words
The hidden
message is anchored (so to speak) by two four letter words: 'test' and
'vere'. Arguably 'vere' is the key word, and of course it's not really
a word, but a proper name. In the 10 spacings I wrote out I found 6 four
letter words. So what are the odds that 2 four letter words will appear
at one spacing? Actually it's pretty high:
(6/10)^2 = 0.36
Clustering
Here is an
engineer's back of the envelope of clustering. I count 20 short (two and
three letter) words at x34 spacing. The odds a short word appearing either
in the column before or after each four letter words is very high (83%):
[1 - (14/34)^2] = 0.83
The clustering we see in the message shows this has happened four times
(0.83)^4 = 0.47
Including 'so', 'i' and 'e'
Above ignored 'so', 'i', e which are in same column as another word. How much do adding them in affect the clustering? Actually they have relatively little impact. There are so many short words (more than 20 if one letter words are included) that the chance of one of them appearing in one of the six columns of the two clusters is about 99.5%, ignoring that less letters are available, so if we allow for this maybe its 96% to 98%. This happens three times so adding in the same column words ('so', 'i', 'e') adds a multiplier of 0.88 to 0.94. Even if we take the lower bound (88%), our clustering probability is reduced only a little
0.47 x 0.88 = 0.41
Above shows that the odds that six of the 20+ shorter words on x34 will cluster with one of the two four letter words is surprisingly high, approx 0.43.
Message structure --- two four letter words with clustering
The odds that
we would see two four letter words with the shorter words we see adjacent
to them forming two clusters? This is the product of the probability above
(probability of two four letter words x probability of six shorter words
adjoining to form clusters).
0.36 x 0.41 = 0.15
So the odds of the (raw) format or structure of the message we see, meaning two clusters each built around a four letter word, is roughly 15%, or one in six to seven. The chance of the raw message format appearing by chance is actually quite likely, one in six to seven, so in and of itself it means little.
Odds of grammatical and relevant?
Now we arrive
at the key question, What is the probability that such seven short words
cluster around two four letter and together with a single short word between
them form a 'message', something that is quasi-grammatical and more important
that is related to the poem and relevant to the monument? I have
no idea how to calculate this, and furthermore I doubt it is possible to
do so.
HIM SO TEST, HE I VOW IS E VERE DE
{'him', 'so', 'test', 'he', 'i', 'vow'} ['is']
{'E', 'Vere', 'de'}
It is like in the Drake equation where some terms, like the 'probability of life arising on an otherwise suitable planet, must simply be guessed at, and guesses range from 1 to infinitesimally small.
Conclusion
Just a plain reading
(without Roper's tweaks and polishing) gives a fairly cogent, grammatical
and relevant message. Written strictly in order with only normal english
spacing and punctuation
HIM SO TEST, HE I VOW IS E VERE DE
or
Him so test, he I vow is E Vere de.
My (seat of the pants) guess here is that the probability that 24 of the 220 letters of the poem (11% of all its letters) can be shaped into ten words forming a quasi-grammatical long string that reads as a message relevant to the poem and monument is pretty damn low. Odds? Who know, but I would guess, maybe less than 1% or 0.1%. Combining these 'make sense' odds with the word format odds (0.15) calculated above reduces the probability by another order of magnitude to 0.1% to 0.01%, or one part in a thousand to ten thousand.
It does appear to me, as someone who has worked with numbers all his life as an engineer, that the likelihood of this being random, not deliberately inserted, is highly unlikely.
Also important is that nothing even remotely similar turned up in the other nine trial spacings I ran.
Also important is the the plain text of the poem has a weird, but suggestive hook that there might be more to the poem than meets the eye, saying "Read if thov canst'.
Also important is that there are multiple hints that x34 spacing should be examined. x34 is twice x17 and Vere in the message is the 17th Earl of Oxford. And as Dr. Bruce Spittle has pointed out only one line on the monument is indented and that line has x34 characters. Well sort of, the line has 34 letters if its 'AE' is not expanded. Finally x34 is close to the average number of letters per line (36 2/3) for a poem that on the monument is quite even and rectangular.
Also suspicious is that the spelling of some words in the plain text appear to have been tweaked for no obvious reason. For example Ben Jonson's poem in the First Folio (see above) contains the words 'writ' and 'wit', but in the monument poem the same two words are spelled 'writt' and 'witt'. The extra 't' in writt is needed to supply the last letter in 'vere', probably its most important word in the message. (The extra 't' is 'witt" may be explained by the fact that it provides a better visual rhyme with 'writt'.)
Another possible spelling adjustment is the word 'whom', which is spelled differently in its two appearances in the poem, on line 2 spelled 'whom' and on line 3 spelled 'whome'. (A possible non-message reason for the 'whom' spelling difference may be that 'e' was left off 'whome' in line 2 to shorten it, because this line is the longest and most crowded line in the poem.)
Look at the spelling 'Shakspeare' on line three of the poem. As I show elsewhere, the missing 'e' after 'k' would easily fit on this line. This oddball spelling of Shakepeare is necessary for the message to appear, but it differs from the spelling on nearly all his published works. The nearly contemporaneous first folio and all quartros of the plays and poems (with two exceptions) spell the author 'Shakespeare'. Aside from this being another suspicious spelling tweak in the poem, might it also have been needed for the local town folk who did not identify this town resident as the author of the plays and poems?
When I add it all up, I think the hidden message is for real!
If real, what does it mean?
First what
is meant by real? I see only two possibilities. Any message being now read
out, be it my more conservative reduced message or Roper's longer more
elaborate message, is either random or it isn't. That is, it is either
a product of pure chance or it has been crafted deliberately into the poem.
Black or white, no in-between here.
Joke or clue to 'real Shakespeare?
Suppose we
grant that it is real, that the encrypted message has been deliberately
inserted into the monument poem in the early 1600's. Does that mean deVere
is the author of Shakespeare's works? Absolutely not! All we know is the
poem author said this. Maybe he was prankster, maybe it is just a joke.
The author of the poem might have doubled over laughing when he thought
about what people in the future would think if/when this was found. But,
on the other hand, it might not be a joke, it might be a clue that Shakespeare
is not the author. Unfortunately, I don't see how we divine the intention
of the author.
Is 'V' in Vere really 'v' in the plain text?
Obviously
the key word in the supposedly hidden Vere message is 'Vere, but notice
that the first 'v' in 'Vere' comes from the 'v' in 'monvment'. This looks
like a weakness, or a possible weakness, to me in the hidden message theory.
Elizabethian printing and/or spelling seems to (often) reverse 'v' and
'u'. I had noted this earlier in this essay before I noticed the source
of the 'v' in Vere. So is the 'v' in 'monvment' really a 'v' or is the
printed 'v' here to be read as a 'u', consistent with the modern spelling?
The 'v' in 'vow' has the same problem, in spades. Here the 'v' comes from 'qvick'. The letter following 'q' (at least in modern usage) is nearly always a 'u', so is that the case here too? Darn if I know, I'm not a scholar of Elizabethian spelling and typography. But it raises and important question (Is the 'v' in 'monvment' really a 'v'?), which if answered in the negative, could doom the hidden message theory!
On a scholarly Hamlet site I found a Hamlet concordance, allowing searches for alternate spellings in four versions of Hamlet (three quartros and the first folio). Here is the result of a search for 'mon.ment' that would find 'monument' and 'monvment'.
(source -- http://www.leoyan.com/global-language.com/ENFOLDED/)
The search result (above) gives up some perspective on the interchangability of 'u' and 'v'. In quatro 6 of Hamlet we find the spelling 'grave' and 'living', but in quatro 2 and first folio of Hamlet we find the spelling in the same line to be 'graue' and 'liuing'. However, in all three versions of Hamlet in which the word 'monument' is found, we find it is spelled with a 'u', not a 'v' as it is in the funerary poem. A search for 'vow.' finds the spelling 'vow' (like in the hidden message) and 'vowe' (like in Shakespeare's dedication to Venus and Adonis). Notice above that 'hour' sometimes is spelled with a trailing 'e' and sometimes not.
Hidden messages in Shakespeare's time
First what
are the odds that a hidden message might be there? Equidistant coding goes
back to antiquity. The book 'Code' discuss battle field coding in antiquity
that wrote messages on long strips used wooden encoding and decoding rods
of the same diameter. This was a form of equidistant coding.
Encoding and
word play was popular in Shakespeare's time. Bacon, a contemporary of Shakespeare,
and was well known for his 'Bacon Cipher' on which there is even a Wikipedia
article. Galileo, another contemporary of Shakespeare, is known to have
used anagrams (rearrangement of letters) to claim priority for his astronomical
discoveries (rings of Saturn and phases of Venus), as did Newton later
in the century.
===========================================================================================================
Ten monument
decode trials
Here are ten
trials of the Shakespeare monument poem I did at spacing of x32 to x40
plus x17 with the longer words I found marked. Procedure: The 220 letter
monument poem is written out by hand in rectangular form on graph paper,
with horizontal widths 32 to 40, and then read vertically (here only downward).
This reveals any text hidden at this equidistant spacing.
Summary word count
Five letter words
0
Four letter words
6
Three letter words
49
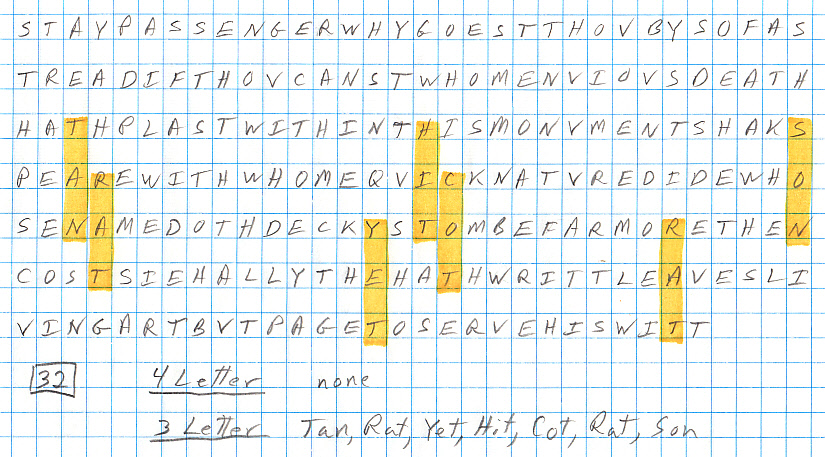
.

.
x34 doesn't looks so impressive when shown this way
does it, with with all the other three and four letter words marked?
Yet, 'him', 'test', 'vow' and 'Vere' are all here
(in this order)

.

.

.

.

.

.
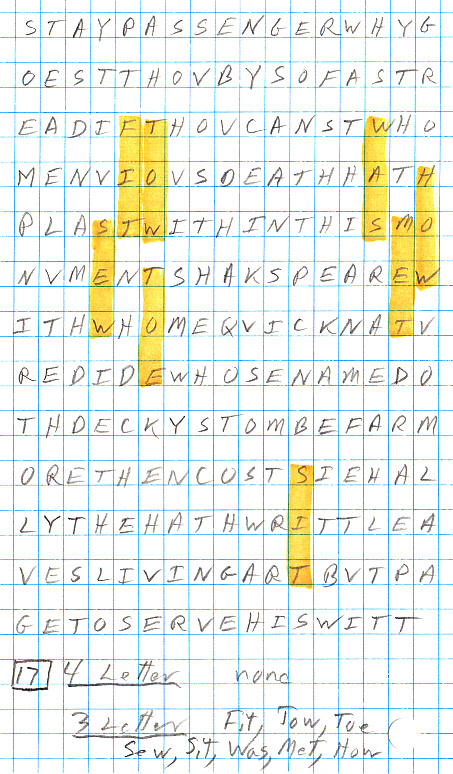
===========================================================================================================
Notes on Latin lines of Shakespeare funerary monument text

Latin lines of funerary monument image
(cropped from a current image above)

1825 Trinty Church booklet
Loose translation
1st:
In judgement Pylian (a wise king), in genius Socrates, in art Virgil (Publius
Vergilius Maro, author of the poem Aeneid)
2nd:
Earth covers, people mourn, Olympus holds
2nd line has a very curious phase -- Olympus (a greek god) possess him. ---- This is in a church, a curious way to say heaven!
Whoops --- below is wrong. The first Latin word in the monument photo does look like 'Iydicio', but I now see that the 2nd letter is a 'v'. What I thought was a tail (making it a 'y'), is just the serif on the capital 'T' below it reaching up and (by accident) perfectly aligning with it.
There is also an oddity in the spelling of the first Latin word. The spelling on the monument is 'Iydicio', but this word does not appear in Latin dictionaries. The church 1825 version (very close to the current monument in most details) spells it 'Iudicio', and this word does appear in Latin dictionaries, meaning judgement. The interchange of 'v' and 'u' is common, but here we see 'y' used for 'u'. Weird.
'Ætatis
53' in the bottom line means 'age 53' (spelled in Latin dictionaires as
'aetatis').
'Æ' of the 2nd Latin line
It
is claimed by Roper and Spittle that the 2nd Latin line hints that 34 is
a decoding key for the cryptogram in the English poem below. I grant the
indent is quite odd. This is a engraved stone plaque and for both size
and appearance reasons it is desirable for all the lines of text to be
about the same length, but the indent of the 2nd Latin line makes its right
end project out further than all the other lines by about two characters.
Quite odd.
Is Æ
one character or two?
Whether the
indent of the 2nd Latin line is a hint, or not, to the decoding key for
the monument cryptogram hinges on whether in Latin Æ is one character
or two. For the line to have 34 characters and be a hint Æ must be
counted as a single character. If it is a ligature (see definition
below) or a scribal abbreviation, then it is really two characters
that are merged as a typographic or writing convenience. If you look at
the pictures of the monument English poem, you will see it full of combined
letters, which I would characterize as the engraving equivalent of 'scribal
abbreviations', and all these must be expanded into separate letters for
the hidden message to appear. So the question on the table is should Æ
be
expanded too?
Dr. Bruce Spittle of New Zealand, who first suggested the indent is a hint, says Æ is one character in Latin. Wikipedia says Æ is one character is old English (and a few other old langurages), but in Medieval Latin it was not one character, it was (or could be) a ligature, (two characters cast together for typographic reasons). Neither the modern, nor earlier versions, of the Latin alphabet show Æ as a letter. A Latin dictionary indicates an internal 'e' is sometime rendered 'ae'. So does this support Spittle, is it saying 'ae' is like an 'e', one character, or is it an alternate spelling?
I have no idea
who is right, it's a very complex topic, but it seems to me that Wikipedia's
suggestion that in Medieval Latin Æ is an optional ligature does
introduces some doubt into the 34 letter count for the 2nd Latin line.
-----------------------
* Dr. Bruce
Spittle of New Zealand, who first suggested the letter count of the indented
2nd Latin line was a hint to the decode key, was asked about Æ and
here is his reply (via email):
"I don't see a particular problem about counting the Latin character, a ligature, Æ as one character to reach a total of 34 Latin characters in the second line in Latin of the inscription. The Shorter Oxford English Dictionary notes that Æ in old English was a simple vowel intermediate between a and e. It was a single character in contrast to a digraph such as ae in which two letters are used to represent a sound. Similarly in Latin Æ was a single character. When Anglicized in it written as a digraph ae. However when counting the Latin characters in the second line it is not necessary to Anglicize the line and the proper count of the Latin characters in the line is, in my opinion, 34 rather than 35."
Wikipedia shows 'ae' in Latin was prior to 5th century
AD represented a diphthong.
** Æ comes from Medieval Latin, where it was an optional ligature in some words, for example, "Æneas" (see Wiki, 'Aeneas'). It is still found as a variant in English and French, but the trend has recently been towards printing the A and E separately. Ref: The Chicago Manual of Style, 14th Ed. Chicago: The University of Chicago Press. 1993. pp. 6.61.
In Old English (Danish, Norwegian, and Icelandic languages) the character Æ is not a typographic ligature. It is a distinct lettera vowel. In modern English orthography Æ is not considered an independent letter but a spelling variant, for example: "encyclopædia" versus "encyclopaedia" or "encyclopedia".Definitions (from Wikipedia)
scribal abreviation --- Medieval scribes, writing in Latin, increased writing speed by combining characters and by introduction of scribal abbreviation. For example, in blackletter, letters with right-facing bowls (b, o, and p) and those with left-facing bowls (c, e, o, d, g and q) were written with the facing edges of the bowls superimposed. In many script forms characters such as h, m, and n had their vertical strokes superimposed. Manuscripts in the fourteenth century employed hundreds of such abbreviations.
digraph -- a pair of characters used to write one phoneme (distinct sound).
diphthong -- literally "two sounds"), also known as a gliding vowel, refers to two adjacent vowel sounds occurring within the same syllable. Diphthong ae is usually collapsed and simply written as e (or e caudata, ?); for example, puellae might be written puelle
http://en.wikipedia.org/wiki/Typographic_ligatureI researched 'Æ' of the 2nd Latin line. If this compound character is not counted as a single letter, then the line has 35 letters and the 34 hint disappears. I see several issues here.
1) What 'Æ' doing in the 2nd line? If this is supposed to be a hint, why complicate it with an ambiguous letter combination?Look at this, 1631 version of poem2) Wikipedia writes phrase containing 'Æ' as "POPULUS MAERET" (note 'Æ' is expanded into two letters) with a translation "the people mourn him" A check of Latin/English dictionaries for the verb 'mourning' yields 'maeror' or 'meror'. (I am far too rusty in my HS Latin to remember what the ending 'et' means, but I see 'videt means 'he sees'.)
** In 39,000 word Latin dictionary both 'maeror' or 'meror' have the same english definition. With this note: An internal 'e' might be rendered by 'ae'. Does this tend to confirm Spittle statement that Æ is one character (effectively) in Latin?
maeret --- mourn
meret --- soldiers pay/whore pay (totally different)
maret --- no entry (spelling in Dugdale. In 1721 Verdue it is mÆret!) ** It does look like Hollar-Dugdale is probably wrong here!
mourn (english) --- maereo, maerere (base words)
cover --- tego, tegere (base words) tegit on monument
http://www.archives.nd.edu/cgi-bin/words.exe?meror3) A long online history of the Latin alphabet (link below) shows Latin evolved from 21 letters at the beginning, long before the Roman Empire, to 23 in the days of the Roman empire, to in the middle ages 25 as 'i' split into ('i','j') and v' split into ('v', 'u'). At this point its 25 letter alphabet was the same as present English alphabet, except no 'w'. By the end of 15th century (Shakespeare's time) the Latin alphabet letter count was up to 26 with the addition of 'w'.
http://www.orbilat.com/Languages/Latin/Grammar/Latin-Alphabet.html============================================================
In 1631, a year before his death, John Weever published the massive Ancient Funerall Monuments, which recorded many inscriptions from monuments around England, particularly in Canterbury, Rochester, London, and Norwich. Shakespeare's monument does not appear in the published book, but two of Weever's notebooks, containing his drafts for most of the book as well as many unpublished notes, survive as Society of Antiquaries MSS. 127 and 128. In one of these notebooks, under the heading "Stratford upon Avon," Weever recorded the poems from Shakespeare's monument and his gravestone, as follows:
Iudcio Pilum, Genio Socratem, Arte Maronem
Terra tegit, populus maeret, Olympus habet.Stay Passenger, why goest thou by so fast
Read if your canst whome envious death hath plac'd
Within this monument Shakespeare with whome
Quick Nature dy'd whose name doth deck his Tombe
far more then cost, sith all yt hee hath writt
Leaves living Art but page to serve his witt.ob Ano doi 1616 AEtat. 53. 24 die April
===========================================================================================================http://shakespeareauthorship.com/monrefs.html
Four
old versions of the monument poem: 1631, 1656, 1721, 1825
With some
sleuthing I found four (very) old versions of the monument poem: 1631,
1656, 1721, and 1825. I am informed by Prof Burgstahler that the graphic
images used by Roper, same as the current plaque, come from an 1880's book.
The oldest, says a Shakespeare authorship site, was found in a notebook
of Weever, who published a book on English monuments in 1631, and who died
the following year. A few years later is an engraving for Dugdale's 1656
book on monuments of rural England drawn by his engraver Hollar. One reference
dates Dugdale's monument original sketches to 1634. Next was drawn by Vertue
for the 1721 Pope edition of Shakespeare's works. The last from a publication
of 1825.
--------------
1631 version by Weever
At the Shakepeare
authorship site below I found a very early reference (1631) to the monument
showing its text. The claim is this comes not from a published book, but
from exant notebooks of an author who published on English monuments. I
copied the relevant sections.
-------------http://shakespeareauthorship.com/monrefs.html(from above)
"In 1631, a year before his death, John Weever published the massive Ancient Funerall Monuments, which recorded many inscriptions from monuments around England, particularly in Canterbury, Rochester, London, and Norwich. Shakespeare's monument does not appear in the published book, but two of Weever's notebooks, containing his drafts for most of the book as well as many unpublished notes, survive as Society of Antiquaries MSS. 127 and 128. In one of these notebooks, under the heading "Stratford upon Avon," Weever recorded the poems from Shakespeare's monument and his gravestone, as follows:Iudcio Pilum, Genio Socratem, Arte Maronem
Terra tegit, populus maeret, Olympus habet.Stay Passenger, why goest thou by so fast
Read if your canst whome envious death hath plac'd
Within this monument Shakespeare with whome
Quick Nature dy'd whose name doth deck his Tombe
far more then cost, sith all yt hee hath writt
Leaves living Art but page to serve his witt.ob Ano doi 1616 AEtat. 53. 24 die April"

Looks like the Dugdale sketch,
but is credited on Wikipedia to Wenzel Hollar (1607 - 1677)
(Hollar was an engraver who worked for Dugdale)
original in Wenceslaus Hollar collection at Univ of
Toronto
(source -- http://upload.wikimedia.org/wikipedia/commons/f/fa/Wenceslas_Hollar_-_Clopton_and_Shakespeare_%28monument%29.jpg)
Below is a close up of the monument poem from the above Hollar/Dugdale engraving image.

Close up of monument poem in 1656 Hollar/Dugdale engraving
of Shakespeare monument
(source -- http://upload.wikimedia.org/wikipedia/commons/f/fa/Wenceslas_Hollar_-_Clopton_and_Shakespeare_%28monument%29.jpg)
Hard to read
word: 1st line, 'so?', looks like 'soe'
3rd line, superscript on 'W' is probably 'th', but hard to read
5th line, 'si?h', could be 'sieh' or 'sith'
Punctuation
hard to read: 1st line, probably a comma after 'Stay'
4th line, might be a comma after 'dyed'
6th line, unclear if there is a comma or period (or nothing) after 'witt'
And not quite as old, this .... Vertue/Pope 1721
I stumbled
across below in the huge Folger Shapespeare online image archive, which
popped up accidentially when searching 'Droeshout', the engraver of the
Shapespeare image in the First Folio. The Folger description is that its
one of three images pasted into a (rare) 1609 edition of Shakespeare sonnets.
It is labeled 'Shakespeare memorial? , so it is probably old, but there
is no date and no engraver (see below). This is close up of the whole monument
image posted above with the other full monument images.
'Ingenio Pylium, Genio Socrates, arte Maronem,
Terra Tegit, Populus Maeret, Olympus Habet.
-------------
Curious changes
What is really curious
with Vertue is all the changes from the standard poem. There are other
versions of the poem floating around with small changes, but this has much
more than I have seen. This could be very old. Is it possible that this
is a sketch for the monument before it was built? Is it possible
that this was the early draft poem later modified to encrypt a hidden message?
(see below)
Even the Latin is changed! Notice the first word here is 'Ingenio', whereas it is 'Ivdicio' (Iudicio) on the present day monument. All the other Latin is the same, there is even a (small) indent in the 2nd Latin line. I went into a Latin dictionary and found that these are two different Latin words, yet both work!
judgment, decision, opinion, trial : iudicium
innate character, talent, nature : ingenium
http://www.thebookmarkshop.com/latin/latindictionary2.htm
The Wikipedia translation of the Latin lines is
"A Pylian in judgement, a Socrates in genius, a Maro in art," comparing Shakespeare to Nestor the wise King of Pylus, to the Greek philosopher Socrates, and to the Roman poet Virgil (whose last name, or cognomen was Maro), and the second line reads "The earth buries him, the people mourn him, Olympus possesses him," referring to Mount Olympus, the home of the Greek gods."Ingenio pylium" search

1721 drawing of Shakespeare monument by George Vertue
at British Museum (clearly a lo-res view of above poem from Folger Shakespeare
library)
(source -- http://www.britishmuseum.org/research/search_the_collection_database/search_object_image.aspx)
http://www.britishmuseum.org/research/search_the_collection_database/search_object_details.aspx?objectid=3236727&partid=1&searchText=George+Vertue%2c+shakespeare&fromADBC=ad&toADBC=ad&numpages=10&images=on&orig=%2fresearch%2fsearch_the_collection_database.aspx¤tPage=2
In this 1721
sketch we see the Shakespeare figure with the quill, paper and cushion
as in the current monument. Note, same crazy position where pen seems to
be writing on the cushion not the paper, which is for some reason under
the left hand. His collar is also the same, but the hair is different,
here bushy. Note the hair on the older BW figure doesn't seem to be the
same as the current moument hair.
----------------------------
1825 Trinty church history
Doing some
Googling I was surprised to stumble onto a version of the monument poem
from 1825 contained in a 26 page history of Trinty Church, apparently put
out by the church. In 2006 a copy held by the New York Public Library was
digitized by the Google book project. When I found the link to this booklet,
I was inside and able to page through, and I screen captured the monument
text it contained (below). However, I did not capure that link, and when
I searched out its title I get lots of hits, but I am unable to search
inside. Hence the 1825 text below may be a new (and rare) find in the monument
poem history.
screen capture from 1825 booklet below
Title: Views of the ancient Church of the Holy Trinity:
Stratford upon Avon, in Warwickshire,
containing the monument of the immortal Shakspeare
Authors: John Preston Neale, John LeKeux, Publisher:
Sherwood, Jones, 1825,
Original at New York Public Library
source (does not open) --- http://books.google.com/books?id=2PojAAAAMAAJ&oe=UTF-8
source (opens) --- http://babel.hathitrust.org/cgi/pt?id=nyp.33433074889720
A search for the title of this book brings up a lot of hits and one of them must open, I just don't know which one.
Four
poem versions compared line by line
Below line
by line is the current monument wording and punctuation compared with four
early versions:
1631 (Weever), 1656 (Hollar/Dugdale), 1721 (Vertue),
1825.
Stay Passenger, why goest thov by so fast?
Current monument (upper case => lower case)
Stay Passenger, why goest thou by so fast
Weever 1631
Stay, passenger why goest thou by soe fast,
Hollar/Dugdale 1656
Stay, Passenger, why dos't thou go so fast?
Vertue 1721
Stay Passenger, why goest thov by so fast,
1825 Trinity church history
Read if thov canst, whom enviovs Death hath plast,
Read if your canst whome envious death hath plac'd
Ref says 'your', but it looks like a misprint
Read, if thou can'st whom envious death hath plac't
Read, if thou cans't, whom envious Death has plac'd
Read, if thou canst, whom envious death hath plast,
With in this monvment Shakspeare: with whome,
Within this monument Shakespeare with whome
W(th) in this monument Shakspeare with whome
Within this Monument; Shakespear, with whom
Within this monvment, Shakspeare, with whome,
Qvick natvre dide: whose name, doth deck Ys Tombe,
Quick Nature dy'd whose name doth deck his Tombe
Quick nature dyed whose name doth deck the tombe
Quick Nature dy'd, whose Name doth deck the Tomb
Qvick Nature dide: whose name doth deck ys. tombe
Far more, then cost: Sieh all, Yt He hath writt,
far more then cost, sith all yt hee hath writt
Far more then cost, sieh all that he hath writ
Far more than Cost, since all that he has Writ
Far more then cost; sith all yt. he hath writt,
Leaves living art, bvt page, to serve his witt.
Leaves living Art but page to serve his witt.
Leaues living art but page to serue his witt,
Leaves living Art, but Page to serve his Wit.
Leaves living art, bvt page to serve his witt.
Version comments
All five are
different! The 1631, 1656 and 1721 differences kill the Roper's (reduced)
hidden message, but the missage does work with the 1825 version, even though
it has a few spelling differences.
The Weever 1631 version is very close to the current monument (accepting 'your' as a misprint for 'thov'), but it wipes out the message by an extra letter in the 2nd line ('whome') and no 'v' in 'monument' wiping out the 'v' need for 'Vere. It differes also in the spelling of Shakespeare with Shake having its 'e',which is missing in the current monument.
The Hollar (1656) text is also pretty close to the modern monument, however the cryptogram is wiped out because most (not all) 'v's are replaced by 'u's. The 1721 Vertue text is surprisingly modern ('since' for 'sieh', 'than' for 'then', 'within' for 'with in', 'plac'd' for 'plast'). The 1631, 1656, and 1721 versios all spell Shakespeare differently!
The 1825 version from a 26 page history of the Trinty church supports the hidden message. Only one of its words is different from the current momunment ('sith' for 'sieh'), however, some of the 'v' are replaced by 'u's. Nevertheless, the two 'v's need by the message ('monvment' and 'qvick') are there.
Importance
of 1825 version -- 'sith' not 'sieh'
I think the
importance of the 1825 version of the funerary monument text is under appreciated.
This version of the poem comes from a booklet written by the pastor of
the Trinity church. Unlike earlier versions, which would have been written
out by someone likely making a single visit to the church (traveling on
horseback), this was produce by men who lived with the monument, and who
had the time and means to examine the engraving close up. And the monument
at that point would have had only 200 years of wear and tear compared with
400 years today.
The local churchmen's version is very close to the current engraving, except they write 'sith' not 'sieh', which is found on the current monument. To me this is a strong argument that the original word was 'sith'. It can easily be postulated that wear or damage to the 't' made it hard to read and that in a later restoration, perhaps many years later with no one having memory of the original, it got changed to an 'e'. If the 1825 churchmen got it right, it wipes out Roper's theory about the importance of 'sieh'.
Y superscript abbreviation (update 11/6/11)
The Stratford
monument has two Y superscript (Ys and Yt) abbreviations, and I found another
one in the First Folio play 'The Tempest' (Ye). In the Second Folio this
'Ye' is replaced by 'the'.
Ys => this 'whose
name, doth deck Ys tombe'
'whose name doth deck this tomb' (Wiki, modern)
Yt => that
'sieh all, Yt he hath writt'
'sith all that he hath writ' (Wiki, modern)
Ye => the 'got
by Ye diuell himselfe' (1st Folio)
'got by the divell himselfe' (2nd Folio)
The pattern seem clear: Y seems to stand for 'th' and the superscript is the next letter or a shorthand for a pair of letters. But look at the five versions of the monument poem above. Three time Ys was written out, and never as 'this', instead its transcribed as 'his', 'the', 'the'. We do not see this weirdness in Yt. It was transcribed twice, both times as 'that'. I don't know what to make of this, but it seems very strange.
Also worthy
of comment is a finding of 'Ye' in a First Folio play. I have found only
one in looking at three or four pages of facsimiles. Is 'Ye' Shakespeare's
usage or a printer's abbreviation? The editors of the 2nd Folio removed
it.
===========================================================================================================
Shakespeare
monument poem images
The monument
text pictured in Roper's document in its punctuation is slightly different
from what I first found (from Peter Farey Marlowe site). What I found looks
like a picture, but Roper's has more of an art look. Below I detail the
(minor) differences between them, which have no impact on the cryptography.
In Miller's document, which has a lot of original source material, there
is a photo of the whole monument (text and bust). When this photo is expanded
the text and punctuation are quite readable, and it is clear that what
I have included in my essay is a close up picture of the actual monument
poem.
The slight difference between the Roper and Farey images of the monument text bother me. It seems like one or both of them have been edited or cleaned up. One or both of them have has been cleaned up. To see if I could clarify the starting point for the decoding I went on a hunt for more images of the monument text images. You would think it would not be that hard to find a high resolution photo of the monument text. However, I am aware that it is so high on the wall that only professional photos of it may exist.
I downloaded all the images of the monument text I could find online that were different, a half dozen or so, and then ordered them. I find there are five versions of punctuation, which I label versions 1, 1a, 2, 2a, 3. Versions 1 are in the form of graphics. Versions 1a is of a copy of the monument. Versions 2 and 2a are photos of the same monument (in Stratford) that can be identified by the pattern of the marble, However, version 2a looks a little different from version 2, so it must have been taken at a different time. Version 3 is an oddball.
The monument reportedly was damaged by vandals in the 1970's requiring it to be repaired. In an email to me from Prof Albert Bergstahler says the (graphic) version Roper was using, same as version 1 graphic images (with 'Canst'), was taken from an 1880 book. This would mean that the BW version 2a photo (with 'Canst') was very likely taken before the 1970's damage repair, and the version 2 photos (with 'Ganst') were taken after of the 1970's repair reflecting the monument as it is today.
The text is identical in all of the images I found (for example, 'Sieh', 'writt', 'witt'.) with the exception that the 'C' of 'Canst' looks like a 'G' in version 2 photos.
Version 1
Colon after
'Dide', small titled question mark after 'Fast', right shifted comma between
'Tegit' and 'Popvlvs', 'Canst'

source -- http://www.cuda.at/joomla/images/stories/monument-inschrift.jpg
(The '+' sign under the 'S' of Socratem is an artifact
of the screen capture)
Another Version 1 (with image reversed)

source -- http://www2.prestel.co.uk/rey/hall.jpg
STAY PASSENGER, WHY GOEST THOV BY SO FAST?
READ IF THOV CANST, WHOM ENVIOVS DEATH HATH PLAST,
WITH IN THIS MONVMENT SHAKSPEARE: WITH WHOME,
QVICK NATVRE DIDE: WHOSE NAME, DOTH DECK YS TOMBE,
FAR MORE, THEN COST: SIEH ALL, YT HE HATH WRITT,
LEAVES LIVING ART, BVT PAGE, TO SERVE HIS WITT.
Version 1a
Note this
is a copy, not the monument at Stratford. It might be at the Shakespeare
Folger library.
It's hard
to read, but it appears to be a modified Version 1 text. It's like
version 1 in that is probably has Colon after 'Dide', small titled question
mark after 'Fast', and 'Canst', but unlike version 1 the comma between
'Tegit' and 'Popvlvs' is not right shifted, it is centered.

Note the border is wood not marble as it is in Trinity
Church
. This is a COPY of the monument (bust + poem) that
is in Trinity Church
Flicker credits this image to Folger Shakespeare Library
Note above shows Shakespeare with both a mustache and a pointed beard. The mustache is hinted at in the cover engraving of the first folio, and the Cobb portrait shows Shakespeare(?) with a beard.
Version 2 (BW photo)
No colon after
'Dide', comma after 'Fast', centered comma between 'Tegit' and 'Popvlvs',
'Ganst', no period after 'Habet'

source -- http://imgf
.imageshack.us/img101/4807/012bfh2.jpg
Another version 2 (color photo)

source -- http://www2.prestel.co.uk/rey/shpear~1.gif
(Note the marble pattern on the sides shows this is
a photo of the same monument as above)
Version 2a
From the marble
pattern this is a photo of the same monument as the two photos above. It's
at an angle and at lower resolution, but still some differences from above
are visible. Most noticeable is 'Canst' not 'Ganst'. 'He hath' looks a
little different from above, but it's possible this is due to lower resolution.
There is a distinct 45 degree line (or crack) running through the 'm' in
'tombe' here. Part of this line is weakly visible in the photos above.

source -- http://www.anonymes-associes.com/wp-content/uploads/2009/03/scannedimage-25.jpg
Clearly a hirres photo of the whole monument (taken
at an angle) with readable text
Shows a hint of a colon after 'Dide'
2nd 'd' in 'Dide' appears to have some damage
(Other pictures show the image to be painted, so this
is a BW image)
Note the two missing finger tips on the hand holding
the quill.
This is likely an old photo taken prior to the 1970's
monument repair.
Version 3a
This is identified
as a "tracing" of the monument in an 1890 book. It appears to be identical
with the B&W photo above.

Mounument tracing in 'Shakespeare's true life' By
James Walter, 1890
source -- http://books.google.com/books?id=6qtDAAAAYAAJ&pg=PA261&dq=Shakespeare%27s+true+life+By+James+Walter+%22special+tracing%22&hl=en&ei=s_mQTv6BHor40gG0rpgL&sa=X&oi=book_result&ct=result&resnum=1&ved=0CDIQ6AEwAA#v=onepage&q&f=true
Version 3b
If above is
a tracing, what is this another tracing? Words and spelling are identical
to above, but there are spacing differences in some letters. Note here
the '5' in (age) '53 is under 'o' in ano, whereas above '5' is in the space
after 'ano'. Also 'v' in 'Ivdicio' and 'v' in 'bvt' are more regular here
than above. It's like this tracing was cleaned up.
Punctuation: Colon after 'Dide', large question mark after 'Fast', centered comma between 'Tegit' and 'Popvlvs', 'Canst', period after 'Habet', no colon after 'Shakspeare'

source -- http://4umi.com/image/book/shakespeare/statue_stratford-inscription.jpg
Color photos of the monument bust
A 2006 hires color
photo of the monument bust (below) on Wikipedia shows no damage to the
fingers. This is consistent with the the BW photo above having been taken
prior to the 1970's before the monument was repaired.

source -- http://upload.wikimedia.org/wikipedia/commons/2/26/ShakespeareMonument_cropped.jpg
Looks like finger damage has been repaired
A higher resolution 2010 photo (below) of the Trinty church back wall (cropped) by Ell Brown posted on Flickr. It's clear from this photo that the monument text we read has been painted with gold paint. The same paint has been used to paint the columns and other parts of the monument. The painting could explain some of the differences is punctuation, for example, any punctuation mark not painted would be very dark and likely not show in a photo.
Note also the monument right (not identified by the photographer). This gives some perspective on the Shakespeare monument. For one thing the complete photo shows it is larger than the Shakespeare monument and higher up. It has a plaque beneath the bust too, but because its text, which is barely visible in another photo, has not been painted with gold paint it is all but invisible at this distance. There are other monuments in this church still larger than the Shakespeare too, like the Cloypton? monument, included in the Dugdale book.

Crop from a hi-res shot of the Trinity church back
wall taken in 2010 by Ell Brown, posted on Flickr
Note plaque on monument right --- Its text is not
visible because it has not been painted.
source -- http://www.flickr.com/photos/ell-r-brown/4974025889/sizes/o/in/photostream/
Monument image with (reduced) message marked
Here again
is the reduced message on x34 graph grid and below an image of the poem
text with the message letters marked in red.

Required and not required
For the message
to appear 'monument' (2nd line) must be spelled 'monvment', because its
'v' provides the 'v' in 'Vere'. In the current monument all modern english
'u' are written as 'v', but this is not the case in many early recorded
versions of the poem (1631, 1656) where, for example, you find in the 3rd
line 'monument', which kills the message, because the 'v' in 'Vere' is
gone. The alternate spelling of 'whome' (3rd line) is required because
its 'e' is the 'e' in 'test'. The oddball spelling of 'writt' (vs writ)
is required to get the second 'e' in 'Vere'.
Some controversies I read about make no difference to the decoding: 'sieh' (5th line) or 'sith' both work, and 'dide' (4th line) or 'dyed' both work.
Scribal abbreviations
I also marked
on the poem image in yellow the many (13) combined letters, most doubles
but even one triple! In decoding these combined letters are expanded into
separate letters. No mystery here as it is clear that this is an engraving
convenience, probably done to save space. In typograph joined letters are
common with two letters on the same piece of movable type called a ligature
(Wikipedia has a whole article on 'Typographic ligature'). Of course the
monument is engraved not typeset, so they are more like abbreviations.
(I got this idea after reading a Wikipedia article on 'Scribal abbreviations',
which says Latin documents copied by scribes in the middle ages are full
of combined letter abbreviations like this.)
Five Shakespeare family tombs in Trinity
Five Shakespeare
related gaves stretch out in front of the Trinity church altar (below,
also by Ell Brown). Left to write: Ann Shakespeare (Shakespeare's wife,
1623), William Shakespeare (1616), Thomas Nash (first husband of Elizabeth
Hall, Shakespeare's granddaughter, 1647), Dr. John Hall (husband of Shakespeare's
daughter Susanna, 1635), Susanna Hall (Shakespeare's oldest daughter, 1649).
Hard to believe the graves/headstones have not been reconfigured. Church
records show it was restored twice in the 1800's. It's more than suspicious
that since this church building is really old (parts of it were built 800
years ago) that all (or nearly) all the tombs in front of the altar come
from one 33 year period (starting with Shakespeare 1616 to the death of
his daughter Susannah in 1649).
The order of the tombs is odd. Will is the big cheese (or so the Stratfordians claim!) and he dies first, but he is neither in the center of the church, the center of the family group, nor at the end, he is 2nd from left. Where is Judith Shakespeare, Shakespeare's youngest daughter (1662), Elizabeth Hall, Shakespeare's granddaughter (1670), and Shakespeare's sister Joan (1646), who lived in Stratford her whole life and died within the time range of the other tombs, or for that matter her husband who died within a week or two of William in 1616? [Wikipedia says Elizabeth is buried in another church. Judith is buried on the Trinity church grounds, but no one knows where, and where Judith's husband (Thomas Quiney) is buried is totally unknown. Nor is there any mention on Wikipedia of where Joan Shakespeare (Hart) is buried. Also Shakespeare had three surviving brothers (Edmund, Gilbert, and Richard) that died between 1607 and 1613. Where are they?] Is this group here because of their support for the church?
A panoramic view of the church shows that to the right of these five tombs here is room for one (or maybe two) more, but the tops appear to be plain. Also the tomb in the dead center, arguably the most important spot, 4th of these five Shakespeare family tombs, which is John Hall.

Panoramic view of Trinity Church altar (Aug 2013)
I stumbled
on this wonderful image showing the whole the Trinity Church altar taken
with an 8 mm fisheye lens. While a fisheye lens distorts it has the virtue
of showing nearly everything. From this photo it is clear that five Shakespeare
family graves (above) occupy five of six (possibly seven) tomb spaces in
front of the altar. On the wall left is the famous Shakespeare bust one
of four on the walls (and there are a couple of more in the back corners
of the altar). Another thing is clear from this photo that this church
was built when architects had figured out how to make a light filled interior.

Holy Trinity church altar taken with 8 mm fisheye
lens
Shakespeare's tomb is 2nd from left (with large sign)
and monument is on wall above
Other photos identifie this as the 'east window' of
the church
(photo credit: Erasmus T --- http://www.flickr.com/photos/erasmus_t/2693291889/in/photostream/lightbox/)
Erasmus T's images
Erasmus T's images
on Flickr are quite stunning, he has posted 1,800 images there. While he
takes realistic photographs, many of his images of historic English building
and countryside, like above, are quite unusual in that he has processed
them somehow to get a painter-like look, for example:
 .
.
Example showing how Erasmus T processes a photo to
get a painter like effect
(source --- http://www.flickr.com/photos/erasmus_t/2764810609/in/photostream/lightbox/)
===========================================================================================================
History
of the Shakespeare monument
I first found
the discussion of the early history of the monument in the link below quite
convincing, but with further work less so. (See my added feather to 1634
sketch in Appendix below.) It's author, Richard J. Kennedy, argues that
the image of the monument drawn as drawn in 1634 by Dugdale, which is clearly
different from the present monument and famously shows the arms resting
(or holding) a woolpack, could very well have been a monument to Shakespeare's
father, who was a former town mayor (or equivalent) and is thought to have
been a wool merchant (some say a glover).
http://webpages.charter.net/stairway/WOOLPACKMAN.htm
An engraving from Dugdale's sketch, which supposedly still exists, was included in Dugdale's large book of monuments published 22 years after the sketch (1656), and the book was reissued in 1730, long after Dugdale's death under another editor with the Shakespeare monument image basically unchanged. A reissue in 1730, more than a century after Shakespeare's death, with monument image unchanged is probably important, because during this time with multiple new Shakespeare folios issued his plays were more widely available and his reputation was growing. Kennedy quotes several observers during this period that confirm Dugdale got it right. The only response from the Stratfordians says Kennedy is that Dugdale got it wrong, but he makes a pretty good case that this is unlikely. Sometime after 1730 the monument figure must have been changed because the man is reportedly now holding a pen.
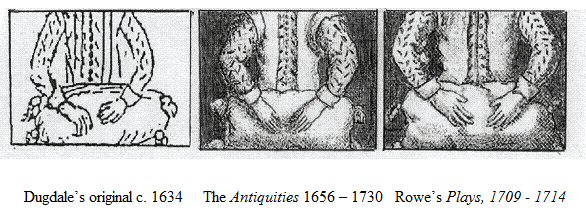
source -- http://webpages.charter.net/stairway/WOOLPACKMAN.htm
Wait
But then I
found below, showing the whole monument from Dugdale 1656 book side by
side with a BW photo of the monument. What to make of this! Every blooming
detail in the Dugdale sketch is totally different from todays monument.
There's only two possibilities I can think of. One, the monument at some
point was totally changed, not just the bust, but all of it. Or maybe,
as sort of indicated by the sketch above left, what Dugdale did is just
make a quick sketch of the bust, and he wrote notes that described the
(classical) elements surrounding the bust. This would be lot quicker, a
lot less work. And might be justified because no one really cares about
the outside details. Then later the plate engraver, say working from Dugdale's
notes and memory fills in the outside. This latter would explain why the
major elements are the same (two top cherubs, dia slash on plaque, top
roof, rounded cupola, two columns, rectangular poem below. This is my guess
as to how Dugdale worked.
But the two busts don't look anything alike, even the heads. How the hell is this explained? Was Dugdale who traveled around for 20 years sketching monuments, just completely unable to draw? Doesn't seem likely since portrait painters seemed to be a dime a dozen in the days before photos.
No fame?
But there is a bigger
point here. This sketch sloppiness (if that it is what it is) throws a
light on Shakespeare fame, or lack of it, in the years after his death.
If he was so famous, why was more care not taken with his monument? It
seems to have been treated like any other monument in the book. (Is this
book available in facsimile?)

On the left is a photograph of the Shakespeare Monument
in Holy Trinity Church, Stratford. On the right is the monument as depicted
in William Dugdale's Antiquities of Warwickshire (1656)
(source -- http://shakespeareauthorship.com/shaxmon.html)
Cushion writing surface?
The writing surface
on the current monument is clearly a cushion or sack. The cushion is lying
horizontal with large gold colored tassels at the two front corners. This
is an extremely odd writing surface, photos of the monument show it to
be rounded and as a cushion you would expect it to be soft. Dugdale had
it right, then the cushion we see today may have been the cushion/wool
sack that the figure originally held, and only the arms and hands have
been changed to hold a quill in the right hand and paper in the left.
But as usual there is one thing that doesn't quite fit. One of the introductory pieces of the first folio (1623) refers to "thy Stratford moniment". Kennedy has no explanation as to why the first folio would refer to it if it represented Shakespeare's father. Did the first folio writer know this, or did Shakespeare deal in wool too?

Graphic of Shakepeare monument pasted into a 1609
edition of sonnets
with provenance back to 1791. (poem closeup in Appendix)
source --- Folger Shakespeare library
http://luna.folger.edu/luna/servlet/detail/FOLGERCM1~6~6~217575~113901:-Sonnets--Shake-speares-sonnets--Ne?sort=Call_Number%2CAuthor%2CCD_Title%2CImprint&qvq=q:droeshout;sort:Call_Number%2CAuthor%2CCD_Title%2CImprint;lc:FOLGERCM1~6~6&mi=68&trs=94
Above historic monument image
Inspection of a
hires version of the above image (at link above) shows it is identical
to the engraving the British Museum identifies as having been done by George
Vertue for the 1721 Pope edition of Shakespeare. When compared to modern
photographs of the monument, this engraving in its cushion and body are
very close to the photographs. The only significant difference is the engraver
has improved Shakespeare's face and hair over the sculpture making his
apprearance more realistic (and giving Shakespeare curly hair). It is clear
from this dated engraving that the monument has not been reworked since
(at least) 1721.
===========================================================================================================
Woolpack man?
Below is closeup
of 'Woolpack' man from 1656 Hollar/Dugdale sketch/engraving of Shakespeare
monument in Trinity church (above). (Idea credit: Richard J. Kennedy for
his article 'Woolpack Man')
http://webpages.charter.net/stairway/WOOLPACKMAN.htm)
 .
.
left: Closeup of the 'woolpack' man from 1656 Hollar/Dugdale
engraving of Shakespeare monument
right: girl racing with a woolpack in 'Tetbury Woolsack
Races and Streetfayre'
Notice both have four ears tied at the corners.
(source left -- http://upload.wikimedia.org/wikipedia/commons/f/fa/Wenceslas_Hollar_-_Clopton_and_Shakespeare_%28monument%29.jpg)
(source right -- http://picasaweb.google.com/marcgibbons1967/TetburyWoolsackRacesAndStreetfayre?authkey=Gv1sRgCP-s3O2v_tXojQE&feat=directlink#5360554028145825234)
Dugdale's
'woolpack' sketch from another perspective
Below left
is what purports to be the original sketch Dugdale made in 1634 of the
funerary monument bust. Notice how the hands are held differently than
in the engraving published in the Dugdale book 22 years later (above).
Center is a photo of the current hands of the monument. Both have one hand
higher than the other (though they are reversed). The feather in the monument
photo is I read a real feather, and it looks real.
The 'Declaration of Reasonable Doubt' makes the difference between the 1634 sketch and current mounument bust on of its four major points:Here's my speculation (original as far as I know). We have to assume here that Dugdale got some details wrong, which clearly he often did. As long as he got the main concept right, I doubt he (or anyone else) cared if all the fussy (and hack) details of funerary monuments were drawn exactly right."The Stratford monument effigy clearly depicts a writer; but it does not look the same as the one erected in the early 1600s. A sketch by a reputable antiquarian in 1634 shows a man with a drooping moustache holding a wool or grain sack, but no pen, no paper, no writing surface as in today's monument. Records show that the monument was "repaired." Apparently the effigy was also altered to depict a writer."
Suppose Dugdale saw the monuument when it had no feather. If we reverse right and left hands, then the hands of the photo and sketch are reasonably close. Also the cushion is not that different either. OK the cushion in Dugdale's sketch sort of looks like it is standing up, but isn't this just another detail. If I visualize a feather (see below right, I drew it in!) in the sketch's left hand (our right), then I could believe it was a (sloppy) sketch of the current monument (sans feather and maybe sans paper).
I would go one step further in my speculation. The paper in the current monument is rather odd. It is not being written on, it just sticks out. It looks like he is writing on the cushion! I see the monument bust as being complete without the paper, in fact maybe even better. I would speculate that the paper might be a later addition. Without ever having seen the monument, my guess is that the hands and cushion are very likely separate pieces. It does not look like it would have been very difficult for someone in the last four hundred years improving the monument by making a (thin) paper piece and slipping it in.
Adding a feather
Dugdale's
'woolpack' sketch from another perspective
Below left is what purports to be Dugdale's original 1634 sketch and right same image with my drawn in feather. I think the feather goes in very nicely. And with the feather added the Dugdale sketch and the monument look pretty close (except for right left reversal). Mystery solved?
 .
.  .
.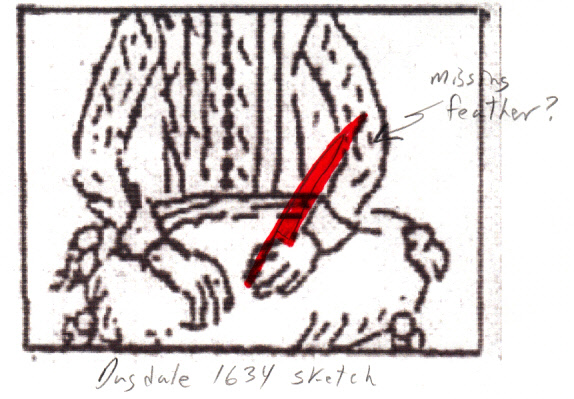
(left) 1634 original Dugdale sketch
(center) photo of monument hands (with real feather)
(right) Dugdale sketch with feather added (by me)
source -- http://webpages.charter.net/stairway/WOOLPACKMAN.htm
Bottom line --- With my speculation Dugdale sketch become consistent with it being a sketch of the current monument (prehaps sans feather and paper). Dugdale's sketch was showing a writer, not a woolman, his hands in writing position on a four cornered (writing) cushion. (However, the cushion in both cases looks to thick (and soft) to write on.)
Crests on top
I notice that
the crests on the Hollar (1656) and Vertue 1721 sketches are pretty close
to each other, even though nothing else is similar, and both are very similar
to the current monument. I wonder if in the engraving studio they had access
to the Shakespeare crest. Crests after all were granted by the crown (upon
payment), so there must have been official records of them. My memory is
that John Shakespeare (Shakespeare's father) bought a crest (yup), and
this is very likely it.

monument crest detail, Vertue engraving 1721
It is pen in the diagonal. Higher resolution shows
the bird above is holding a similar pen
Note angel left has his hand on an hourglass
source --- Folger Shapespeare library
http://luna.folger.edu/luna/servlet/detail/FOLGERCM1~6~6~217575~113901:-Sonnets--Shake-speares-sonnets--Ne?sort=Call_Number%2CAuthor%2CCD_Title%2CImprint&qvq=q:droeshout;sort:Call_Number%2CAuthor%2CCD_Title%2CImprint;lc:FOLGERCM1~6~6&mi=68&trs=94

monument crest detail, Hollar engraving < 1677
http://upload.wikimedia.org/wikipedia/commons/f/fa/Wenceslas_Hollar_-_Clopton_and_Shakespeare_%28monument%29.jpg
Sketched from a verbal description?
The bust sketch
is so puzzling. It differs in virtually every way from the modern
version. It's not just that Shakespeare looks totally different. The top
of the columns here have lions on top, and their tops do not line up with
the top of the arch. The crest shares a diagonal line with the modern version,
but all the outside scroll work is different. The two angels are in a different
place and holding a shovel and hourglass, neither of which is present in
the current monument. It's like Hollar never made the trip (on horseback!)
to see the monument, but someone described the monument to him and that
was the basis for the sketch. For example, I can see Hollar drawing above
if he was told: crest is a shield with diagonal pen, above an armor helmet
and sitting on the helmet a bird , curculies drape the shield. An angel
holds an hourglass.
Or alternately,
rather than doing a finished sketch on site, he did a rough draft of the
bust and just made notes about the outside. This would make sense. Later
doing the final sketch for publication in the studio, and not remembering
the details of the monument and maybe not considering it very important,
he worked from his notes.
===========================================================================================================
Introduction
In this appendix
I preserve my first write up of the monument poem decoding even though
my views of it being a cryptogram have changed: going from, 'it very likely
is a cryptogram' to 'maybe it's a cryptogram'. The text below was written
soon after reading the papers on the subject, so it reflects mostly the
pro views of the advocates. But after putting my skeptical hat, researching
the monument, digging into the arguments made by the advocates, and doing
my own probability calculations, my views shifted. The core problem with
the funerary monument is that math only takes you so far. It gives some,
limited support to the claims of it being a cryptogram, but far from convincing,
and from there it's clues, coincidences and hidden messages the advocates
really want to hear. Hardly the basis for certainty.
-------------------------------
Stratford
monument poem -- first write up
Hidden
messages generally have a bad reputation. People have pulled a lot of strange,
hidden messages from the Bible for example. It turns out that if you are
allowed to 'read' a document in many different ways and importantly
the document is long, then the probability of finding a few hidden
messages is pretty good. But the exception to this rule seems to be a hidden
message in the inscription on the Stratford monument (to Shakespeare),
which was erected around the time of the first folio in a church at Stratford-upon-Avon
and still exists. The inscription is thought to have been written by Ben
Jonson. Here is the hidden message David L. Roper has located in the poem:
"So test him, I vow he is E. De Vere as he, Shakespeare name, B.I." or (cleaned up a little) "So Test Him, I Vow He Is De Vere" (B. I. is thought to refer to Ben Jonson)
What makes this very interesting is this (says Roper):
1) Inscription on the monument is very short, only 220 letters, and the message uses over 10% of these letters (23 letters)Read all about it here:
2) An equidistant code is used and spacing is 34, which is very suggestive since Edward de Vere was the 17th Earl of Oxford.
3) The message is (fairly) grammatical and clearly says 'he is de vere'.
4) The plain text of the inscription seems a 'little off' as it would be if it was cover text. Furthermore it includes a challenge which (absent a hidden message) seems to make no sense, saying, "Read if thou canst"
5) A confirming message can (with some contortions) be pulled from the plain text. "QVICK NATVRE DIDE" in plain text => (with some manipulation) 'Sum Vere' in Latin => 'I Am Vere' in English.
http://www.dlroper.shakespearians.com/content.htm
New
Roper links
1994 paper http://174.122.112.226/~rwest/gm2_dr.htm
Ray West page links to Roper and Rollett http://174.122.112.226/~rwest/gm2_rw.htm
Shakespeare funerary monument (update 5/31/2011)
The link above
(to D. L. Roper) is dead. I remember reading a pamphlet many years ago
that detailed the decrypting, and I might still have it, but have not searched
it out. (Can't find it.) I always wondered if the output was really as
clean as the author presented it, so I decided to see for myself if the
code below would appear by taking every 34 character.
"So test him, I vow he is E. De Vere as he, Shakespeare name, B.I." ??
For more on the poem variants see the appendix
I downloaded
all the poem and monument images available online that had high enough
resolution for the text to be readable. I found four or five variants in
the punctuation. All have the identical text (SIEH, Writt, Witt, etc) except
for one variant where the first letter in 'Canst' sort of like a 'G'. Comparing
all the images, several of which are clearly photos of the Stratford monument,
I think the 'Ganst' variant (color image above) shows the monument poem
as it currently is. What appears to be an older BW photo shows parts of
two fingers missing has 'Cant' in the text. I read there was vandal damage
to the monument in the 1970's and a subsequent repair, so my guess is that
the BW photo shows the poem areal of the monument before the 1970's repair
and 'Ganst' variant (color above) shows it after and currently. Luckily
none of this affects the search for a message because the word in question
was (and is) clearly 'Canst'.
Just looking at the photo I tried to read out (counting by 34) the (claimed) beginning of the code: 'So test him'.
The text begins with 'Stay passenger' and the claimed message starts with 'So test him', so I just assumed the 's' beginning the message was the first 's' of the text, but this doesn't work. So already things are looking more complicated. With a little fooling around I found that the message starts at the second 's' in 'passenger'. OK, with a valid starting point I thought I could just read out the message by writing down every 34th character. This works for a while, you get the first six characters of the purported message ('So test'), but it fails on the 7th character, where 'h' (of 'him') is two characters off.Several issues immediately arise
Do you count spaces? Do you count punctuation? How to decode compound letter combinations, like merged 'TH' in 'thou' (1st line) in 'then' (5th line) and 'Ys' (line 4) and 'Yt' (line 5). Do you use the Latin text? The answers I found after a few minutes (getting out 'So test') is don't count spaces or punctuation, consider merged letters as separate letters, and the small letters in Ys and Yt come second. Don't use the Latin text.
Thinking about what to do next I realized the way to find where the next part of the message was hiding (if it was there!) was to rewrite the message text (without spaces) as lines of 34 characters. 'So test' and any other message phrases encoded in '34 code' would then be visible vertically, and I remembered seeing figures like this in the original pamphlet. Below is my 34 char/line write up. I have put red around the message fragments that have turned up. [No fudging here, this is all the raw poem text (Latin is excluded) from the photo, and agrees with original text on Wikipedia -- 'Shakespeare funerary monument', just rewritten in lines of 34 characters.]

My rewriting the Shakespeare funerary monument poem
(with original spelling) in packed lines of 34 char/line
and reading message fragments vertically
Whoops --- I marked 'I' 'vov' because I thought that
was how you spelled 'vow',
but 'I vow' is there, two column to the right of 'test'
Well I find the message text is there (sort of) mostly as the author claimed. From left to right:
* 'So test'
is adjacent to 'him'
* 'He' 'is'
('i' in is is shared with 'BI')
* 'E Vere'
is adjacent to 'De'
* 'I vov'
and this leads immediately to (written horizontally) 'Shakespeare'
* Linking
into Shakespeare from above are 'as' and 'he'
* 'BI' (supposedly
Ben Johnson, the author's, initials) is lower center ('i' is shared
with 'is')
So with some arm waving I get, reading vertically left to write {compared to what the original author wrote}
Him, so test, he is E Vere (De), I vov [Shakespeare] as he (B I)
{So test him, I vow he is E. De Vere as he, Shakespeare name, B.I.}
A real message?
So is this
a real message or a mixed up mess of short words we are organizing into
a coherent message? Who knows. But I will admit (with zero experience ever
doing this before) that there are what appears to be some startling
relevant quasi-phrases emerging, and emerging is approximately the right
order, and especially impressive in that the code is every 34th letter
and Edward De Vere was the 17th Earl of Oxford.
And when I look over all the vowels, I can find relatively few other words in the vertical columns. Here is the complete list (left to right): 'pit', 'hop', 'cess', 'are', 'tin', 'rove', tee', 'set', 'rot', 'ham'.
Confirmed?
I have not
tried, as did the original author, to figure the odds of this, but looking
at the relevant phrases with their approximately right ordering vs the
few other words that do show up and the huge number of possible short English
words, I would have to say, like in 'Myth Busters', that I confirm that
this probably is a real encoded De Vere message!
----------------
Roper's '34 char' analysis of the funerary poem (6/2/11)
While the
link above containing 'dlroper' is dead, 'dlroper' appears to refer
to someone named David L Roper, and I found his home page, which is active
with material dated as recently as 2011 (first two links below). He also
has stuff on another URL (dlropershakespearians.com), 3rd link below.
http://davidroper.eu/
http://davidroper.eu/Cryptology%2021.10.pdf
http://www.dlropershakespearians.com
http://www.dlropershakespearians.com/Inscription%20as%20a%20cryptogram.pdf
After some poking around on his site, I found his analysis of possible hidden message in Shakespeare's funerary monument poem by taking every 34th char. It's somewhat hidden, embedded in an essay called 'Cryptology'. This is dated 2009, so it cannot be the same document I read many years ago, but I'm pretty sure it's the same basic analysis. Whether this analysis is original to Roper or not I do not know, but I vaguely remember reading years ago him making a point that his contribution was a mathematical analysis of how improbable it was, so it's possible that this decoding of the monument poem may be from the 19th century when the search for hidden codes was popular. (update --- In other of his articles on a different URL he claims to have come up with the idea of applying an equidistant code to the monument text to look for an encrypted message and to have done the work in one evening. I can belief the latter, a few such charts can be made up by hand is a short time and it takes only a couple of minutes to read them.)
David L Roper-----------------------
David L. Roper is a character and no way do I identify with him. His web site says he writes on "literature, philosophy, mathematics". Literature and philosophy turns out to mean he writes on Shakespeare and Nostrodamus. He is a follower of Nostradamus, writing a book about him saying he never made a mistake and his predicted dates are "pinpoint" accurate. In his Shakespeare work Roper claims to have definitely solved all the Shakespeare authorship problems!Two David L. RopersHe also considers himself a mathematician of a high order (though I suspect of the crackpot school), claiming to among other things to have come up with a solution to Fermat's last theorem using only mathematics available to Fermat! He submitted it to a peer review math journal, but it has not been accepted yet, which he puts down to "cognitive dissonance".
I at first thought Roper had also written a lot of book on religion, but it turns out that a google search for 'David L. Roper' finds two writers with this name and all the religion book are written by the other one. Apparently to differentiate himself from the religion writer our Roper omits the period from his middle initial: 'David L Roper'.Nevertheless, even with his quirks and frequent smug assertions that he is 100% right, I find his writings on Shakespeare to be interesting and worth reading. He writes well, and in his arguments he often makes a lot of good points. He appears to be a smart, clever guy (no bio, so I have no idea what his background is). His writing spans a wide and unusual range (mathematics, Shakespeare, ? Nostradamus!). One of his books ('Proving Shakespeare', published 2009) is sold on Amazon ($50!), but has no reviews.
Tacking the problem
To start I
applied x34 spacing decoding strictly reading out the raw message
with no changes in word order or letter order. This leads to a shortened
and somewhat less grammatical message than its advocates see, but (see
below) clearly still very interesting and relevant. Below is the (reduced)
raw message, with only a comma added, that I am going to examine. With
the strict criteria I have used the Ben Jonson's initials that its advocates
point to is gone, because to get it they reverse the (I B) letter order.
HIM SO TEST, HE I VOW IS E VERE DE
Note a shorter message is clearly more likely (actually much more likely) than a longer message to occur by chance, so if the odds of a shorter message being a statistical fluke are found to be small, then the point is made that someone deliberately encoded deVere's name into the monument poem. I venture no opinion about what this might mean as far as who wrote Shakespeare is concerned. My objective is very limited, to just estimate the probability of the text above arising by chance.
Procedure
First take
a guess (I don't see how it can be calculated) that the text above,
clearly relevant and quasi-grammatical, could have arisen by chance.
I can hear you yelling foul, I am just guessing the answer! Not really,
because the strength of the case for the message being real is that are
a lot of supporting (auxiliary) probabilities that also need to be factored
in. This is things like the message uses more than 10% of the letters of
the poem, there are multiple odd spellings of words in the poem like the
spelling of Shakespeare as 'Shakspeare' (omitting the center 'e'), the
plain text of the poem contains a suggestive hook ('Read if thov canst'),
the equidistant spacing of 34 is twice 17 and deVere was the 17th Earl
of Oxford, and more.
Each of these auxiliary probabilities multiplies the original guess and can substantially reduce the final odds. To show the power of this suppose each of four independent probabilities is quite likely, say with a probability of 0.25 (25%). This reduces the guesstimate odds by a factor of 256 since [(0.25)^4 = 1/256]. If the four auxiliary probabilities are each 10%, then the reduction in odds is by a factor of 10,000, since [(0.1)^4 = 1/10,000].
Strength of the argument
There are
so many auxiliary probabilities to be factored in here that it doesn't
matter all that much what is initially guessed. Mathematically this is
the strength of the argument that the hidden monument text is real, not
a statistical fluke. When many probabilities need to be multiplied together,
which is the correct procedure if they are mathematically independent (meaning
unrelated to each other), it greatly reduces the odds of the text above
appearing by chance. (Roper has a long list of these auxiliary factors.)
The actual
number range will very depending on who does the estimating, but the important
point is that if the number comes out tiny, this is all that matters. When
I plug in what I consider to be conservative numbers for the individual
probabilities, I get final odds (in round numbers) of 'one in million'
or less. And this is starting with an initial guess that I think is quite
high, 1% to 0.1%, for quasi-grammatical and relevant text, like
above, to arise by chance.
===========================================================================================================
 .
. 
(left) Alice Pleasance Liddell (age 6 in 1858)
(right) poem in 'Alice's Adventures in Wonderland'
photographed
by Charles Dodgson, pen name Lewis Carroll
ALICE PLEASANCE LIDDELL
(source -- http://en.wikipedia.org/wiki/Alice_Pleasance_Liddell)
(first letter of each line)
The mathematics
of the 'Alice's Adventures in Wonderland' acrostic hidden name are unassailable.
While there may be a lot of lines in the Alice book, the odds that by chance
a 21 letter name, the real name of the little girl thought to be the inspiration
for Alice and to whom the book is dedicated, would form from the first
letters of a poem with 21 lines, i.e. from 21 consecutive lines
with no skips or reversals, is effectively zero.
===========================================================================================================
Overview
of probability vs word length
The odds that
a particular name (or letter string) will show up by chance depends on
the number of letters it contains and which letters (common or uncommon).
Below is a table of letter frequency in general english (compiled by Beker
and Piper). Note the wide range between letters with the most common letter
'e' at 12.7% and least common 'q', 'x' and 'z' at 0.1%, a range of x127.
Can we use this to come up with a 'rule of thumb' as to how the chance
a name will arise by change varies with its length?
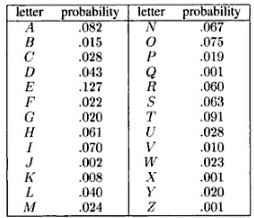
Letter frequency in English (by Beker and Piper)
Average for all letters
Well, first thought
is just to find the average of all the numbers in the table. It's
a starting point, but it will be crude because it does not account for
whether letters are common or uncommon. The average comes out to be (see
below) .0385 (or 1/26), so as a first order estimate we can say increasing
a name length by one letter makes it about 26 times less likely to occur
by chance.
1st column
542/13 = 41.7
- a,e,i,h,j
200/8 = 25.0
2nd column
459/13 = 35.3
- o,n,r,s,t,q,x,z 100/5 = 20.0
all 26 letters 1001/26 = 38.5
=> 3.85% or (1 part in 26)
Vowels and consonants
But we can come
up with a better 'rule of thumb' by separating vowels and consonants and
grouping consonants according to their numbers in the table. Let's calculate
the average letter frequency for four groups: 4 vowels, 5 most common consonants
(> 6%), 12 moderate frequency consonants (0.8% to 6%), and 5 least common
consonants (< 0.8%).
4 vowels
a (8.2%), e (12.7%), i (7.0%), o (7.5%)
=> 8.85%
5 most
common consonants
h (6.1%), n (6.7%), r (6.0%), s (6.3%), t (9.1%) =>
6.84%
13 moderate frequency
consonants
300/13 => 2.31%
4 least
most common consonants j (0.2%), q
(0.1%), x (0.1%), z (0.1%)
=> 0.125%
So what do we do with four categories? For a conservative estimate (on high side) we can assume that for each consonant there is a vowel, so lets pair them up and figure the geometric (multiplicative) mean. The geometric mean is the odds multiplier per (added) letter.
vowel x high freq consonant
8.85%, 6.84% => 7.78% or
(1 part in 12.8)
vowel x mod freq consonant
8.85%, 2.31% => 4.52% or
(1 part in 22.1)
vowel x low freq consonant
8.85%, 0.125% => 1.05% or
(1 part in 95.2)
We can simplify things by combining the pairs with high and moderate frequency consonants, since their probabilities are less than a factor of two apart.
vowel x high & mod freq consonant
7.78%, 4.52% => 5.93% or
(1 part in 16.9)
vowel x low freq consonant
8.85%, 0.125% => 1.05% or
(1 part in 95.2)
This simplified things nicely. Pairing vowels with consonants (a conservative assumption), but excluding the four least likely consonants, gives us an average letter frequency of about 6%. This means extending a letter string by one letter reduces the odds it arise by chance by about 17 and for two letters 17^2 = 289.
If a vowel-consonant pair includes one of the four least common consonants (j,q,x,z), which arise according to Beker and Piper in general english only once in 500 to a 1,000 letters, then it's about 5.6 times less likely for one letter added (5.6 x 17 = 95) and 5.6^2 = 31 times for two letters added (31 x 289 = 8,960).
Five letter string odds estimate
To figure
the odds of a particular five letter string arising by chance anywhere
in a selected grid the first step is to locate one letter of the string
on the grid. This then specifies the location (or two locations is reading
up or down is allowed) of the remaining four letters of the five
letter string. The interim calculation is to multiply out the odds for
the remaining four letters (two vowel/consonant pairs). From our
Rule of Thumb above we find if the string has none of the four rare consonants
(which is likely since they are rare!) the odds are
289 x 289 = 1 part in 83,500
If the string has one of the four unlikely consonants, then we combine the odds of a typical pair with a rare pair and get a result x31 times larger as follows:
289 x 289 x 31 = 2,590,000
I think the easier way to think about this is if a name or word has one rare letter, find this on the grid and use it as the starting letter. Then the interim odds four the four other (more common) letters of the string would be (from above) 1 part in 83,500. To find the odds of the five letter name (or word) arising on any of say 33 grids then the 83,500 needs to be divided by 33 and divided again by the frequency of the rare start letter (probably 1, 2, or 3). In round numbers this gives us final odds for a five letter string on any grid of:
83,500 divided by (1 x 33, 2 x 33, or 3 x 33) = 2,500 to 840
This justifies the round number estimate used in the text of 1,000 to 1 for a particular 'typical' five letter string arising on any grid, and is the same estimate that John Rollet come up with in his Sonnet dedication paper. Every additional letter (above five) raises the odds of the string by a factor of 17 and by another factor of 5.6 if the letter is a rare consonant.
These numbers
are consistent with trial runs I did looking for long words in a bunch
of grids. I found a few four letter words, but not a single five letter
word in any of the ten grids I did of the funerary poem (220 letters in
grid). If the odds of a particular five letter words is say 40,000
to 1 (80,000 to 1 divided by 2 for with 2 start letters) for in one grid,
then it's 4,000 to one for ten grids. So how many five letter words are
there? Tough to say exactly. I have seen lists online of like 8,000 words
of five letters, but about 90% are so obscure I don't recognize them, so
maybe in a 10,000 word vocabulary 1,000 to 2,000 words are five letter
words. This would make the odds of finding any word in the ten grids
(1,000 to 2,000)/4,000 or 25% to 50%, which is generally consistent with
finding none.
===========================================================================================================
Equidistant
vs grid decoding
The proponents
of equidistant decoding (probably following the lead of David Roper) a
fond of calling text written out in rectangular or block format and read
vertically (like below), a 'Cardano grill' or 'ELS (Equidistant Letter
Sequencing) Cardano grill', after Girolamo Cardano, who in 1550 proposed
using a grid for writing hidden messages. Sound classy, but this is not
really how Wikipedia describes a Cardan grill (see Wikipedia 'Cardan
grille'). I prefer to just call it a grid.
sonnet dedication
To check text for hidden messages encoded with equidistant spacing you don't absolutely have to use a grid. You could write the text out in a long string and do a lot of counting and marking of letters at specific spacings, but it so much easier to write out the text in a grid whose width is the specific spacing to be examined. Now any equidistant coded 'messages' is easily seen, you just read vertically. The use of graph paper (as in my scan below) makes doing a grid even easier as you just need to write a letter in each box.
Grids are so natural I have little doubt that those who did the encoding worked with grids, probably sketching out many as they worked to hide a 'message' within the text. (Doing this kind of encoding must be somewhat akin to creating a crossword puzzle.)
Theory vs practice
The theory
may be that the encoding is 'equidistant', but in practice it's
really encoding and decoding using 'grids' at specific spacings combined
with reading vertical. Why am I making this distinction? For two reasons.
How are the cases of reading upward and words that span two columns to
be handled? On a grid both practices look fairly natural, or at least not
unreasonable. They are, it must be admitted, extensions (minor extensions),
and it does seems that they weaken the purity of this type of decoding,
at least a little. However, I don't think there is a hard and fast rule
here, it's a matter of preference, but I am bothered (a little) in that
any preferences, choices, or options introduced into decoding can be a
cryptographic red flag.
Reading upward
Reading upward on
a grid is not as easy as reading downward, but it's not all that hard.
So should reading vertical upward be allowed? Maybe, it's a matter of preference.
Rollet (see 'IOTH' above) and Roper do it, but I don't like it. Reading
upward on a grid after all is effectively reading (in an equidistant manner)
backwards through the text, something I never see pointed out, whereas
reading downward is reading forward.
Words that
span two columns
When reading
vertically, what about wrapping a word to the next column? I do this
above with 'IO'. One pro argument is that this looks like the vertical
equivalent of what is done in normal writing all the time, where a word
is split (with a dash inserted between syllables) and wrapped to the next
line.
Another, and I think stronger, pro argument is that text in grid format has a sort of vertical and horizontal symmetry. When the text is written out horizontally (on a grid), the text is just considered as one long string and is wrapped from line to line. When being read out vertically, cannot it just be viewed the same way, as one long string wrapped vertically from line to line? I think so. Or at least this is my preference over reading upward (and backward). As shown above, in the case of the sonnet dedication, adopting this vertical wrap viewpoint allows to me to find all the fragments of 'Wriothesley' ['wr' 'io' 'th' 'esley'] without having to read upward as Rollet does.
The con argument
of vertical wrapping to the next column is that the purity of 'equidistant'
coding is violated. Granted. If you wrap the text around, butting its end
to the beginning to form a continuous string, and count characters, you
will find that the spacing between the two letters 'io' is 19 not 18. So
from an equidistant theory point of view, not clean, but from a
practical
grid point of view, I think it is clean.
===========================================================================================================
Prof Albert
Burgstahler's view
"The
most detailed and compelling example is undoubtedly that discovered by
David L. Roper in the famous Stratford monument inscription dating from
the early 1620s." ... "Using a simple arithmetical procedure to decipher
the part in English, Roper found a unique plain-text message concealed
in a 34-column ELS grille, whose presence by design is confirmed by additional
encryption related to the two lines in Latin above the six lines in English.
The decrypted message, signed with the initials B. I. for Ben Jonson (I
= J), reads:
SO TEST HIM, I VOW HE IS E DE VERE AS HE, SHAKSPEARE: ME B. I.
(1) In Sonnet 76 of Shake-speares Sonnets published in 1609, de Veres authorship is directly and unequivocally declared in a 14-column equidistant letter sequence (ELS) Cardano grille containing his name de Vere in column 9 of the grille, reading upward into my name in line 7 of the sonnet (line 16 in the grille).
(2) Similar ELS grilles appear in equally unequivocal testimony by well-educated contemporaries that Shakespeare was Edward de Vere in: (a) the Stratford monument inscription apparently written by Ben Jonson, (b) the 1640 poem beginning Poets are borne not made by Leonard Digges, and (c) the dedication to Shake-speares Sonnets of 1609 by Thomas Thorpe.
Burgstahler view of Roper's findings in the funerary monument can be found here:
http://kuscholarworks.ku.edu/dspace/bitstream/1808/5891/3/BurgstahlerCentennial%20ENCRYPTED%20TESTIMONY.pdf
===========================================================================================================
Baconian
decoding is all nonsense
I had never
paid any attention to long standing claims by Bacon supporters that they
had found hidden codes proving their man was the author, but how could
I write an essay an essay on the mathematical strength of Shakespearean
cryptograms without at least taking a quick look at Baconian claims?
Friedmans'
Shakespearean cipher book
In reading
about cryptograms I kept seeing references to a classic book from 1957
titled: 'Shakespearean
Ciphers Examined: An analysis of cryptographic systems used as evidence
that some author other than William Shakespeare wrote the plays commonly
attributed to him', by cryptologists William and Elizabeth Friedman.
William Friedman was a famous cryptologist, head of the Army Signal divison
that broke the Japanese diplomatic code in 1940. The book is out of print,
but I found I could buy (used) copy on Amazon for $7, so I bought it and
read it. Two Amazon reviews (both 5 star), one of them by me. Here is my
Amazon review:
Title: Destroys old Baconian decodes, but what about newer Oxfordian decodes?70 years of Baconian decoding --- all total nonsense
September 16, 2011, By Donald E. FultonThe search for secret codes or messages hidden in the works of Shakespeare has long had a very bad reputation. Much, perhaps most, of the credit for exposing 70 years of decoding nonsense by Baconians goes to William and Elizabeth Friedman, both professional cryptographers with a long interest in Shakespearean decoding. (William Friedman for years headed the US Army Signals Intelligence Service, which broke the Japanese diplomatic code just prior to WWII.) In this 1957 book they explain in understandable terms what the various authors tried to do and how they all miserably failed.
In the late 1900's and early 20th century a huge number of books and articles were published by dozens of enthusiastic amateur sleuths who scoured the works of Shakespeare looking for (and finding!) hidden signatures and messages showing that Francis Bacon wrote the works of Shakespeare. The Friedmans show convincingly that the various approaches these Baconians invented to decode Shakespeare were (with one exception) fatally flawed, essentially nonsense, so pliable that with dogged effort and a little creativity virtually any message or signature could be found. Rather than do calculations, as I had expected, the shoot down is usually accomplished with an explanation of the flaws and a counter example; the Friedmans' will use the decoder's method and quickly find something like,'William Friedman wrote these plaies'.
Baconians originally got the idea to look for hidden signatures or messages that Bacon might have included within Shakespeare because Bacon had actually invented, and described in a book, a code now called the 'Bacon biliteral cipher'. Sounds sexy, but it is actually a simple binary code where two font types ('a' or 'b' flavor) of five consecutive letters (2^5 = 32, enough for an alphabet of 24 letters) in the open text code one letter of the message. The book devotes several chapters to the work of the leading exponent who used the biliteral cipher, a woman they knew personally and once worked for.
While the Bacon biliteral cipher has the advantage of being cryptologically valid in theory, they show there is no evidence that it was employed, and given the technology of 16th century printing it is unlikely it could have been made to work. No one else could duplicate the decodes of the master decoder, one Elizebeth Wells Gallup, which alone indicates that font differences she claimed to 'see' were largely in her head and chosen (without her being conscious of it they think) to make the message work. Also they argue the many variations in 16th century printing (ink spread, paper imperfections, poorly made type) made it all but impossible to successfully implement a subtle binary font code.
This book was published more than 50 years ago and now the Oxfordians are doing some Shakespeare decoding. Is the Oxfordian work all nonsense too? Well human nature doesn't change, and much of the Oxfordian decode procedures, while very different from the old Baconian decodes, I find pretty ad hoc and too 'creative' for my taste, but not all. There are one or two Oxford decodes I find (as an engineer) to be pretty interesting, interesting enough so that I duplicated the decoding and have written an essay ('Shakespearean Cryptograms') for my home page. I bought and have read the Friedman book to get some perspective on earlier Shakespearean decode work.
The most interesting Oxford case, I think, is 1997 decode by Dr. John M. Rollett of the dedication to Shakespeare's sonnets. Here is what makes this case so interesting:
1) Text is very short, only 144 letters
2) The sonnet dedication text and format are both very odd (period after every word, and a strange line format). It has been
suspected for years that it might be a cryptogram.
3) Decode procedure is simple, just write out the text on graph paper, read down (or up/down)
4) Decode yields a 16 letter full name (Henry Wriothesley)
5) Name found is relevant to the sonnets (leading candidate for W. H.)
6) Odds of a specific name arising by chance can be calculated, because it requires a specific sequence of letters, and letter
frequency of the dedication is known exactly (by counting).
7) Five letter first name ('Henry') and five letter fragment of last name ('esley') each contain a 'y' of which there is only 1
in the 144 letters of the dedication.
8) The odds of a specific five letter name (or string) with a 'y' is about 1,000 to 1, which makes the odds of two five letter
strings (in same name, both with a 'y') about a million to one.
9) The line format and word-periods taken as key to a word skip decode yield a grammatical phrase possibly relevant to the
author of the sonnets. ('These sonnets all by ever (E. Ver)')My writeup on this Oxfordian decode (with references) can be found by Googling "Shakespearean Cryptograms" (with quotes)
The Friedmans show convincingly all the Baconian decoding, all of it, was total nonsense. With one exception all the various decoding methods used by the Baconians were fatally flawed (anagrams, numerology, root codes, etc), so flexible that almost anything could be read out of the text. Most of these amateur cryptologists had no understanding of probability, they never calculated the odds of their solutions arising by chance, in fact the idea of doing so never even seems to have crossed their minds.
Bacon biliteral cipher
And what about the
one scheme that was cryptologically valid, Bacon's own biliteral cipher?
Friedmans should know about this, because when they were young they both
worked for a while under a lady who was its leading exponent. They devote
nearly half the book to this valid (in theory) code, showing convincingly
there is no evidence that it was ever used. In fact they argue that sloppy
printing of the 16th century made it almost impossible to use, and also
no one could duplicate the work of the leading biliteral decoder of Shakespeare's
works, even Mrs. Friedman who for a time was her assistant. They conclude
she was not a fraud, but deluded herself into seeing what was not there.
The difficulty of deciding if a letter font was 'a' or 'b' type allowed
for a lot of letter choice in the message, allowing someone who was creative
to 'read out' what they wanted.
But why did Bacon's followers put so much effort looking for hidden codes in the works of Shakespeare they thought Bacon had written? Two reasons. One, Bacon wrote about a code he had invented (Bacon biliteral cipher) describing in detail how by varying a letter's font a hidden message can be inserted into text. It was a binary code with the font of five consecutive letters in the open text translating to one letter in the message (Bacon gave the decode alphabet). The 2nd reason was the look of the printed text of the First Folio. It is easy to notice a striking and apparently arbitrary use of different letter fonts in the texts, particularly italic fonts, so this is where Baconians started to look. It did not seem all that outlandish to them that the font variations in the First Folio might indicate that a biliteral cipher was being used.
Hidden codes in pop music'Some Acrostic Signatures', by William Stone Booth, 1923
Came across this is a recent New Yorker article: Taylor Swift in her CD liner notes uses capital letters to encode hidden messages about which of her boyfriends her autobiographical songs are about!
First up in a Google search were articles claiming they see hidden messages in the first (spoken) lines in plays of the First Folio. An old Baconian book ('Some Acrostic Signatures', by William Stone Booth, 1923) includes the table below of the first (spoken) lines of the plays in the First Folio in order. (Well that is what it purports to be, but apparently Booth can't count because there are only 35 lines here, and there are 36 plays in the First Folio, but this doesn't affect his argument.) He calls this an 'acrostic', a word which I had never heard before, but which has an excellent Wikipedia article, saying, it is a "form of writing in which the first letter, syllable or word of each line, paragraph or other recurring feature in the text spells out a word or a message."
The Baconians say they can read out Bacon's complete name (first and last name) from the first letters of the words of the first lines of each First Folio play in order. Sounds impressive, no? Well not really. Let's look at how they do this. From the first letters of selected words below they read out the name below. (They read forward from 'B' for the last name, and read in reverse from 'F' in the last word for first name.)
FRANCISCI BACONI
And with all these these acrobatics they read out not 'Francis Bacon', which is there, but the possessive form of his name in Latin. Why? His latin name, FRANCISCUS BACONUS, is longer than the possessive form, but it is there but only with a messy overlap of the last syllables of the first and last name. I guess now we can now guess why the odd possessive latin form of the name was chosen by the Baconians, but all this is a quibble.
Look how many words there are in the figure below, the first letter of each of them available (as an acrostic) to be chosen according to the Baconians. There is something like 300 letters (35 lines with 8 to 9 letter/line average) from which they select out 15 they need to form the name 'FRANCISCI BACONI'. (In the original text the letters they pick are identified by capitalization. To make them clearer I drew a black box around them.)
Looking at the beginning. After they get 'B' and 'A', they skip 78 words before they find a word beginning with 'C'! There's are similar huge skips in the reverse read between 'F' and 'R' and 'I' and 'S'. (The Baconians called the skipped words 'nulls', apparently to to downplay the huge gaps.) On its face (prima facie) this procedure this looks very dubious, with 300 letters (equivalent of more than ten full alphabets!) won't enough skipping generally get you the letter you are looking for? Yup. Can't you spell out a huge number of names with this many letters to select from? Yup. What are the mathematics of this?
I was going to do a calculation, but quickly realized a single counter-example would make the point that with their technique you can read out just about any name you want. I decided I would try to find another name, and for fun the first name I tried was my own. I did what they do reading forward and in reverse, and sure enough there is my name (letters marked with red box):
Donald E. Fulton
I quickly found 'Don Fulton' ('Don' reading forward from beginning and 'Fulton' reading in reverse from end), then saw (in just the right place!!) I could add in 'ald' to make 'Donald', and son of gun, there between by first and last name was my middle initial too, 'E'. Yikes, who would have thunk it? I guess this means (according to the Baconians) I must have written Shakespeare!

Baconians: FRANCISCI (in reverse) BACONI (forward)
(in black)
me: 'Donald E. (forward) Fulton (in reverse)' (in
red)
original from book 'Some Acrostic Signatures'
by William Stone Booth (1923)
and reprinted in 'Setting Record Straight'
by Kenneth R. Patterson (2000)
(source -- http://www.sirbacon.org/pattonstrs.htm#double)
My counter-example name was the first name I tried and finding it took all of 5 minutes! I think this makes the point that mathematically this whole Baconian procedure, this Baconian cryptogram (acrostic) is pretty much a joke. It has almost no mathematical rigor. Yet the Baconian author introducing this forward/reverse acrostic cryptogram yielding 'FRANCISCI BACONI', says:
"We come now to the last part of our work, and, for me, the most intriguing. Here is a cipher that, as far as I am concerned, proves the Baconian argument." (Kenneth R. Patterson)The Baconian author makes a big point of the fact that Bacon initials (B, F) appear in the first and last words, ignoring the fact that the order is reversed (while my two names come out in the correct order!), and that very likely this is why this why this type of cryptogram was selected in the first place. What can you say, self delusion. Or total lack of checking for any result other than the one they wanted.
Bacon 'Bote-swaine'
cipher
The Google
search turned up another Bacon cryptogram from a different site (link below)
and different author, Penn Leary, that also involves the first spoken line
in a play. Here the claim is that the name Bacon is encoded in a single
word 'Bote-swaine', which is the first (spoken) word in the first play
in the First Folio. 'Bote-swaine' is the first spoken word in the Tempest
(see above) and is a character addressing the ship's boatswain. I found
this cryptogram at the link below, which is site of Penn Leary (now deceased),
author of "The Second Cryptographic Shakespeare" (1990)
http://www.baconscipher.com/BTSWN.html
Thomas Jefferson coded diplomatic messages using letter
substitution
The decoding
the Baconians are using here they trace back to Thomas Jefferson. I researched
this and indeed Jefferson when he was Secretary of State under Washington
is credited with inventing a 'wheel cipher' machine (see below) that was
used to encode and decode diplomatic message sent to France. According
to the description on the Monticello web site each disk has the alphabet
in random order. To encode the disks are rotated to spell out (a
few words of) the message, then any of the other 25 readings can be sent
as the scrambled code. The decoder has an identical set of disks.
He sets the wheels to match the received code, then by rotating the stack
he can find and read the message. These disks provide 25 possible random
letter substitution codes.

Thomas Jefferson cipher wheels
COOL JEFFERSON WHEEL CIPHER (center message)
(source -- http://wiki.monticello.org/mediawiki/index.php/Image:Wheelcipher_lg.jpg)
As the Baconian Leary describes it, what he is doing is a letter substitution code where letters are replaced by letters of the alphabet just shifted 'x' counts forward or backward. For example, advancing four letters forward would replace 'a' with 'e', 'b' with 'f', 'c' with 'g', etc. (Jefferson's disks would do this if the disks were simplified by having their letters ordered: a, b, c, etc.)
This sounds interesting and mathematically promising because the starting word is very short (only 10 letters) and has a privileged position (first spoken word in the First Folio). All the letters are advanced by the same count, so you can only transform 'Bote-swaine' into as many letters as there are unique letters in this word, which is 9.
Bacon not possible
I note right
away a problem. The start word, 'Bote-swaine', defines the relative
letter
spacing and none of its letters are close together ('s' to 'w' is closest),
but the first three letters of 'Bacon' are the first three letters of the
alphabet, hence it is not possible to get out 'Bacon' from 'Bote-swaine'
by making a simple alphabet shift. I was curious as to how this Bacon decode
was going to work.
First problem --- the alphabet. It's pretty clear from looking at a lot of Elizabethan text that to them the modern english pairs 'u,v' and 'i,j' were (in some sense) interchangeable. Many references state that the Elizabethan alphabet had 24 letters. Jonson's book 'De Augmentis' is said to include an alphabet of 24 letters with 'j' and 'u' not included. 'w' is widely seen in Elizabethan texts, but apparently it was a fairly new letter replacing a double 'v' (or double 'u'), in fact sometimes still printed as two 'v' touching. But the alphabet Baconian author Leary uses in the decryption, which he calls Bacon's reduced alphabet, has only 21 letters! What? Not only are 'u' and 'j' missing, but 'w', 'x', and 'z' are missing too. Why? I don't know. Is there good evidence that this is the way Bacon did his encryption work, or does Leary use it because it gives him the answer he wants?
I checked the history of the english alphabet in Wikipedia, and it confirmed that in the 16th century there were three differences from the modern 26 letter alphabet, all in the process of closing: interchangeable pairs 'u','v' and 'i','j' were splitting into distinct letters, and 'w' firmed up as a distinct letter rather than as a double 'v' or 'u'.The second, and biggest, problem --- What Leary finds is not the name 'Bacon', but a so-called alternate spelling whose pronunciation is 'Bacon'. Well at first this didn't seem too unreasonable because Elizabethan spelling is somewhat phonetic. The problem is that the Baconians have identified a lot of alternate spelling which they consider to be equivalent to 'Bacon'. How many? A dozen? No, they are candid enough to say there are 278 spelling that to them mean 'Bacon'! Yikes, it's going to be a lot easier to find Bacon's name if it can be spelled 278 ways!
What Leary gets from from 'Bote-swaine', using his 'reduced' alphabet substitution with a shift of +4, is below. Note 'b' to 'f' and 'o' to 's' are straight forward, but to get 'B', first letter of Bacon, from 't' only works because the alphabet is 'reduced', a whole bunch of letters at the end ('u', 'w', 'x', 'z') are inexplicitly missing!
Bote-swaine => F S B I A C E N R I
Does [F S
B I A C E N R I] look like Francis Bacon to you?
It does to Mr. Leary. First ignore 'RI', not part of the name says Leary.
'FS' you see is the abbreviation of Bacon's first name, Francis. Leary
tells us that Bacon used this abbreviation. Well OK. And 'B I A C
E N', what is this? Well, says Leary this is a phonetic spelling of 'Bacon'.
Really? Yup, one of 278 alternate spellings of Bacon that the ever flexible
Baconians recognize! Leary also refers to 'B I A C E N' as "another homophone
for his last name", but Wikipedia says "homophone is a word that is pronounced
the same as another word, but differs in meaning." Whoops.
===========================================================================================================
Ben
Jonson's First Folio poem --- an elaborate Cryptogram?
Below
is an example of a claimed cryptogram solution (by James Ferris) that claims
dramatic findings, but when you dig into it you find the the text is read
out using flexible decoding and the detection of significant patterns (S
and Arrow pattern) in word location. Now it can be argued that who knows
what was in the head of the encryptor, the decoder has to go with what
he finds. While this approach may make sense to the true believer, it can
cause eyes to roll among skeptics. It is asking a lot of people to accept
that findings obtained with flexible ad hoc decoding. I don't believe this
is the way to convince people that at least some Shakespearean cryptograms
are real. It doesn't convince me. The concern with elaborate decoding is
that it may be all too easy to 'see' patterns that may not be there. Better
I think to stick with simple decoding when making the case to skeptics,
which at this point is most people.
Below I do some calculations and show that it's two four letter strings, which you would expect to be its strongest element, are actually quite likely to arise by chance. There's an 8% probability of finding a grid that has two 'Vere' that also has two 'de'. If the probability calculations include the odds that the locations of the two 'de' should be near the two 'Vere', which in fact they are, then it pushes down the probability of this occurring by chance to about 0.4%. If it is a cryptogram, it mathematically has only moderate strength even after being 'rigged' (see "two caveats" below).
First Folio Ben Jonson poem
Is the Ben
Jonson poem opposite the engraving in the First Folio a cryptogram? No
one claims it is (later I found Ferris' claim), but it's worth a check.
The wording of this poem is quite odd.

First Folio opened to Ben Jonson poem & engraving
(cropped)
(source -- http://www.haverford.edu/library/special/images/shakespeare_large.png)
To the Reader.
This Figure, that thou here seest put,
It was for gentle Shakespeare cut,
Wherein the Grauer had a strife
with Nature, to out-doo the life :
O, could he but haue drawne his wit
As well in brasse, as he hath hit
His face ; the Print would then surpasse
All, that was euer writ in brasse.
But, since he cannot, Reader, looke
Not on his Picture, but his Booke.
Before graphing this up I did a Google search and son-of-a-gun I found there is a 2008 claim that this is cryptogram by Dr. James S. Ferris at the link below. He says he finds stuff at x20 and x22, but on a quick look it's not obvious exactly what. He says he looked at 41 different spacings and that in twelve of them he finds "stunning and meaningful encipherments". This is a little hard to swallow. Of the 12 he says x20 and x22 were the clearest. This is the first I have heard of this claim. A google search of Dr. James Ferris turns up no bio information or other works (except for a short story). He signed the Declaration of doubt, but lists no affiliation.
http://www.drjsferris.com/Page_Three__.html
Ferris makes this bold claim about his findings in the First folio engraving poem:
"Thus, within the equidistant letter sequence shifts of ELS 20 and ELS 22 of the Jonson Commendation of the Droeshout engraving, is perhaps the most elegantly designed ciphertext in the entire body of the study of ciphers and codes, and Shakespeare."Ferris reading
![]()
Prettied up version of raw x22 grid (below) of First
Folio poem
with Dr. James S. Ferris' S and Arrow (spear) patterns
(above is my scan after copyrighted original by James
S. Ferris)
(Ferris original here -- http://www.drjsferris.com/Page_Three__.html)
I am skeptical of such elaborate decoding and reading.

(raw) scan of my x22 grid of First Folio Ben Jonson
poem
(with 'u's => 'v's)
key words found --- two ['Vere' + 'de' (nearby)]
Original by Dr. James S. Ferris
Cooking the books and salting the mine!
Mr. Ferris,
the good Oxfordian I assume he is, has a problem. He would like to find
'Vere' in a grid of Ben Jonson's First Folio poem, but the facsimile of
the poem (above) as printed in the First Folio shows it contains no 'v's
(none, zero, nada!), so the odds of 'Vere' popping up on any grid is exactly
zero.
This problem does not arise in the sonnet dedication or the funerary monument,
both of which have lots of 'v's.
Note I am going to assume that the facsimile poem above is definitive. Ferris's work is not the main focus of this essay, so I did not take the time to research this. The above facsimile is a high resolution copy of a First Folio from a reputable institution. (I am aware that there are some (minor) differences between virtually all copies of the First Folio).So what has James Ferris done? In his grid everywhere there is a 'u' in the poem, he replaces it with a 'v'! The grids in his paper have 16 'v's and 0 'u's. Now I have not yet read though his paper looking for his justification for this (if any), but I will speculate that he says one of the following:
a) Sneaks it in (no justification)
b) Waves his arms and says something like 'u' and 'v' are interchangeable
c) Employs a more subtle argument. Something like some particular word
is normally spelled with a 'v' and here we find a 'u', so this is hint
(or key) by Jonson that as a first step to decode the cryptogram we should
swap 'u's for 'v's.
If I was a betting man, I would put odds on b).
Calculating the odds
Let's calculate
the odds of 'Vere' with a 'de' nearby appearing twice on the
same grid. The table below shows my count of letters and calculated letter
frequencies in the First Folio poem. For the number of grids I will use
82 = (2 x 41). 41 is the number Ferris used, but there is a quasi-hidden
doubling, because Ferris included the title of the poem in the grids, but
he could just have reasonably excluded it. Another factor of two comes
from words being read up or down.
|
|
in 283 letters of First Folio poem |
Folio poem letter freq |
English letter freq |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure the odds of two 'Vere' on a grid
I will do the calculation
in steps. Let's start with the longest string (Vere). The probability of
one
'Vere' appearing on a particular grid: (This is not an exact calculation,
but it's reasonably accurate. Inside the brackets are the odds that 'ere'
will be adjacent to a 'v', and this is scaled by the number of 'v's on
a grid and x2 for up/down direction.)
V
e
r
e
16 (v) x 2 (up/dn) x [ (1) x
.134 x .067 x
.134] = .038 or (1 chance in 26)
The probability of two 'Vere' appearing on a particular grid is 1 chance in 26 squared or (1 chance in 676). But there are 82 = (2 x 41) possible grids so the probability of two 'Vere' appearing somewhere, i.e. on any one grid, is 1 chance in (676/82) or (1 chance in 8.25) or 12%. There are so many 'e' and 'v' in the poem that odds are greater >10% one grid can be found that contains two 'Vere'.
Figure in the odds of two 'de'
Now we need
to figure the odds of two 'de' appearing on the same grid with the
two Vere. This is calculated as two 'de' appearing on a particular
grid. First we will calculate the odds of one 'de', then square it for
two 'de'. Since the 'de' is a short string quite likely to arise by chance,
to do this calculation accurately it needs to be done as [1 - (not 'de')].
There are six 'd' in the poem, so there will be six 'd's on every grid.
If there is to be no 'de' on a particular grid, then none of the
12 locations adjacent to the 'd's (six above and six below) can be an 'e'.
Odds of (at least) one 'de' on a particular grid = [1 -
((283- 38)/283)^12]
= [1 - (.866)^12]
= [1 - .177] = 0.823 (82.3%)
The odds of two 'de' on a particular grid is this number squared (0.823^2 = 0.68) or (1 chance in 1.5). These numbers say 'de' forms easily by chance. Most grids would be expected to have at least one 'de', and more than 2/3rd of grids would be expected to have two. The presence of one or two 'de' on a grid carries almost no statistical weight.
Relative locations of 'de' and 'vere'
Finally we
need to figure the probability that a 'de' occurs (somewhat) near a 'Vere'.
I don't see how to calculate this exactly, but for an x22 grid with separated
'Vere' we can make an estimate. Let's consider 'de' is near 'Vere' if it's
within 0 +/- 3 columns of it and in the same vertical half (top or bottom).
The odds the two 'de' will be in the right columns is thus (7/22)^2 = 0.1
or (1 chance in 10). The odds that one of two 'de' will be in the
upper half and one in the lower half is 0.5 or (1 chance in 2) (since the
odds of two up is .25 and two down is .25). Hence the odds that both 'vere'
will have a 'de' nearby is (1 chance in 20) or 5%.
Another viewpointSumming up
Divide a grid into equal size regions, for x22 about six looks right, two of which contain a 'Vere', then we figure the odds that the one 'de' will arise in each of these two particular regions. The odds for the first 'de' are (1/3), since both target regions are empty, and for second 'de' are (1/6), since only one target region is empty. Thus the odds that one 'de' will arise in each of two particular regions of six are [(1/3) x (1/6) = 1/18] or (1 chance in 18).
Odds caveats
While odds
of 1 part in 250 may seem like moderate strength mathematically, it comes
with two big caveats. One, there are no 'v's in the original of
the First Folio poem! The cryptogram solution depend totally on
a very questionable change of all the 'u's to 'v's.
'v' in 'picture'Two, calculating the odds after the fact for the exact words found [two 'de' + 'Vere'] is misleading. There are a lot of variants that would happily be accepted by Oxfordians if it contained one 'Vere' or better, one 'Vere' + 'de' nearby. With a little creativity other words that might pop up can often be woven into a relevant phrase with Vere. The more acceptable variants there are the lower the odds.
Look at the last line of the x22 grid above. Note the 'v' in the lower 'Vere' comes from the 'v' in 'pictvre'! What, you didn't know 'picture' was spelled with a 'v'? If you don't buy this, then Ferris' x22 cryptogram solution is kaput. I did Google searches of the last line of the First Folio poem with 'u's and then 'v's. Here's the results:"Not on his Picture, but his Booke" 12,900 hits
"Not on his Pictvre, bvt his Booke" 0 hits
Ferris Footnote
I read through
the essay on Ferris's site where he covers this decode (work in progress
he says). The following is relevant to my review above.
-- I find no
justification, or even mention, of the switch of all 'u's of the poem to
'v's in the grid.
(I am informed by Ferris that he does explain the 'u', 'v' switch in the
text, so maybe I may have missed it.)
-- He begins
with the First Folio poem in facsimile similar to what I have, showing
no 'v's.
Grave epitaph
In the same
essay Ferris covers a lot of ground. He has included several ELS grids
on the four line Epitaph poem over Shakespeare's grave ('Good friend for
Jesus sake forbeare'). He has multiple versions of it at x14 spacing which
shows his pliable decoding technique. The engraving has abbreviations with
superscript: ye and yt. In some grids he writes them out (like in the funerary
monument decodes), and in other cases he drops the superscripts. This adds
another factor of two to possible grids.
Pictures taken in Trinity church show the Epitaph engraving on the grave stone is badly eroded and to the viewer is upside, so the church has made a copy for visitors that sits loose just above the grave (see photo of graves above and below). This white letters on a black background copy is what you normally see in photos. On the copy the first word of the 3rd line (at low resolution) looks to be 'BLESE', but photos of what is probably the engraving on the gravestone and the copy at high resolution (below), appear to show a bridge from the 'S' to the 'E', which makes the spelling 'BLESTE', where 'TE' are merged, the engraving equivalent of a typographic ligature. I checked the 1825 church booklet and (sure enough) it spells it 'Bleste'. Wikipedia also says 'bleste'. However, Ferris, apparently covering all bases, uses both spellings in his grids. This adds another factor of two to the number of possible grids.

Copy of the gravestone Epitaph at Trinity Church,
Stratford on Avon
Notice 3rd line, 1st word has a combined 'T' and 'E',
so spelling is 'Bleste'
source -- http://www.pinepoint.org/uploaded/photos/Learning/ISP_09/shakespeare_grave_rubbing.jpg)
===========================================================================================================
Shakespearean
spelling
Until recently
I had never concerned myself with Shakespearean spelling, but I found a
great resource for viewing and searching Shakespeare's original spelling
(in facsimiles) at Univ of Victoria (link below). My focus was on Shakespeare's
usage of 'u' and 'v', which is central to the sonnet 76 (potential) cryptogram.
Consistency of Shakespearean spelling
I found a
great resource for the checking of Shapearean spelling in an Internet Shakepeare
site run by Univ of Victoria in British Columbia (link below). They have
hi-res facsimiles of all of nearly all of Shakespeare's works: poems, sonnets,
plays (not only Folio1, but Folios 2, 3 & 4) any page of which can
be viewed. They also have a very useful advanced search that can restrict
search to facsimiles, particular works, and even allows for search of a
single letter. (Search, however, is a little buggy. I have found search
is much more sucessful if the search is restricted to the first few letters
of a word, say 'ver' instead of 'verse'. I emailed them about this
problem.)
http://internetshakespeare.uvic.ca
Internet Shakespeare Home
http://internetshakespeare.uvic.ca/Texts/search.html?e=Son_Q1
Advanced search page
I checked 'u' and 'v' words by viewing pages and searching in three works of Shakespeare: Venus and Adonis of 1593, sonnets of 1609, and First Folio of 1623. It is generally thought that Shakepeare participated in the publishing of his first published work, the long poem Venus and Adionis. Venus and Adonis has a dedication to Henry Wriothesley signed, "William Shakespeare". In 1593 Shakespeare was 29, just beginning his career, and de Vere was 43. The sonnets of 1609 were thought to have been published without help from Shakespeare, and in that year de Vere had been dead for five years. Preperation of the First Folio, containing most of Shakespere's plays, was done long after both Shakespeare and de Vere had died.
From this history the primary docment to see how Shakespeare spelled words must be Venus and Adonis (including the dedication page). All three of these works, published over a period of thirty years, had different publishers and different editors. Therefore I find it quite remarkable, given the flexibility of Elizabethan spelling, how consistent is the Shakespearean spelling across these three large works.
However, the consistency if 'u' and 'v' usage is gone when we get to the 2nd Folio published only nine years after the 1st Folio. Now we see 'u','v' spelling much closer to modern usage, both 'u' and 'v' appear inside words and both can start words. 'u', 'v' usage in the 2nd Folio is totally different from earlier Shakespeare works. Did the English language change that much in nine years? Did the new editor change Shakespeare's spelling? Or maybe the 2nd Folio editor understood that 'u','v' usage was not that of Shakespeare, but the spelling preference of the 1st Folio editor and hence felt free to substitute his own spelling preference. I don't think there is any way to really know. Just adds more uncertainty to Shakespearean 'u','v' spelling.
There is also some 'u','v' spelling variation across various quartos of some of Shakespeare's plays, like Hamlet, published while Shakespeare was alive, but this not ought to be taken too seriously as they were thought to have been semi-pirated publications where even text varies between the quatros, sometimes whole scenes being omitted. Some of the play quartros are referred to by cholars as "bad quartros".'u' and 'v' in Shakespearean spelling
 .
.
'u' (left) and 'v' (right) searches in Venus and Adonis
dedication (signed by Shakespeare)
(source --- Univ of Victoria, http://internetshakespeare.uvic.ca)
Shakespeare's u,v spelling convention is clear in the above texts:
a) 'u' never begins a word, it is only used inside
b) 'v' begins words, it is never used inside
except in titles in capitals where 'v' can replace 'u' inside a word
Shakespeare begins words with 'v' that in modern English that begin with 'v', like 'vowe' and also words that in modern English would begin with 'u', like 'vupolisht' (unpolished). Inside text words we find no 'v's only 'u's. We find words that in modern English would be spelled with a 'u', like 'your' and 'count', and also words that in modern English would be spelled with a 'v', like 'haue' (have) and 'inuention' (invention). The word 'suruey' (survey) in the next to last line shows both usages of 'u'.
Exceptions: In a few title pages and dedication headings printed in capital letters what in Shakespearean text is printed as an (inside) 'u' in the title is printed as a 'V'. I have only seen this when the the titles or heading are all in capitals. Examples: title page, 'VENVS AND ADONIS' (1593), dedication page of Rape of Lucrece (1594), "TO THE RIGHT HONOVRABLE". Honourable is also in the text of the dedication and here is spelled with an inside 'u', 'honourable'. The tradition of printing a 'u' as a 'V' in headings and memorials has a long history. It can be seen in cornice spellings on many building built in USA in late 1900's and early 20th century, below is the engraving over the main entrance to MIT. (I used to think this use of 'V' was because 'U' was hard to engrave, but that can't be right as lots of the engraved letters are full of curves.)

'V' for 'U" in engravings over MIT main entrance
Cambridge campus built 1916
Remarkably spelling consistency across Shakespeare's
works
I find the consistency
of Shakespeare's spelling (I only checked 'u' and 'v' words) across his
works over 30 years with different publishers and editors quite remarkable.
The same u,v pattern noted above is found, without exception as far as
I could see in sampling and with searches, in the texts of the poem Venus
and Adonis, then the sonnets and later in the First Folio, but not, alas,
in the Second Folio of 1632, nine years after the First Folio. Unless there
was some printing convention (of which I am unaware) that might explain
this, it probably (or maybe) indicates that this really reflects the spellings
in the Shakepearean manuscripts from which the publishers were working.
Here are the results of some seaches of all of Shakespeare's works in original spelling using Univ of Victoria site (below). The first columns is what you find.
vp, vpon, vse
no search hits for up, upon, use
quick, but
no search hits for qvick, bvt
It's worth noting that the words 'quick' and 'but' both occur in the Stratford monument poem, but there are spelled 'qvick' and 'bvt', spellings Shakespeare never used. Of course, the monument poem may very well not be by Shakespeare (Jonson is the favorite), but there is another explanation. The monument poem is engraved in all capitals. So it looks very much like the reason we see 'V's in the engraving is the convention of printing inside 'U's as 'V's in titles, headings and on cornices.
Wikipedia ('u')
-- During
the late Middle Ages (1400's) two forms of 'v' developed, which were both
used for its ancestor u and modern v. The pointed form 'v' was written
at the beginning of a word, while a rounded form 'u' was used in the middle
or end, regardless of sound. So whereas 'valor' and 'excuse' appeared as
in modern printing, 'have' and 'upon' were printed 'haue' and 'vpon'. By
the mid-16th century (mid 1500's), the 'v' form was used to represent the
consonant and 'u' the vowel sound, giving us the modern letter 'u'. Capital
'U' was not accepted as a distinct letter until many years later.
In other words'de Uere' is not equivalent to 'de Vere'
'u' begins life as a positional variant of 'v'. The positional usage described in the Wikipedia article ('v' beginning, 'u' inside) matches Shakespeare's usage. First letters are usually consonants and vowels typically are inside, so over time 'v' came to represent the consonant sound and 'u' the vowel sound . Wikipedia says this shift happened fifty years prior to Shakespeare, but this does not look right as Shakespeare always puts 'v' at the beginning and 'u' inside. The slow development of capital 'U' probably explains why 'V' is found inside words of titles that are all capitals.
Reference for Shakespearean spelling
I found a
great resource for the checking of Shapearean spelling in the Internet
Shakepeare site run by Univ of Victoria in British Columbia, Canada (link
below). They have hi-res facsimiles of all of nearly all of Shakespeare's
works: poems, sonnets, plays (not only Folio1 , but folios 2, 3 & 4)
any page of which can be viewed. They also have a very useful advanced
search that can restrict search to facsimiles, particular works, and even
allows for search for a single letter. (Search, however, is a little buggy.
I have found search is much more sucessful if the search is restricted
to the first few letters of a word, say 'ver' instead of 'verse'.
I emailed them about this problem.)
http://internetshakespeare.uvic.ca
Internet Shakespeare Home
http://internetshakespeare.uvic.ca/Texts/search.html?e=Son_Q1
Advanced search page
Waste of time?
As a check,
I did a little research on the Second Folio. It was published in 1632,
only nine years after the First Folio. It is basically a page for page
reprint of the First Folio with some spelling changes, having been re-typeset
by a different printer. Second Folio claims, like the First Folio, to be
'published according to the true original copies', yet according to Wikipedia
there are 1,700 differences, mostly in spelling. One researcher looking
at many of the 124 exant copies of the Second Folio found an obvious misspelling
on the title page, the word from First Folio 'according' spelled 'accodring'.
This is a spelling error on the title page in huge print above the engraving
of Shakespeare! Talk about sloppy printing.
As I detail below, the Second Folio text, and the new intro poem by Milton too, completely trashes the u,v spelling conventions of the First Folio. So in looking at Shakespeare's printed works, are we looking at his spelling or the spelling of the printers and editors? The question is, Did the Second Folio editor fix or modernize (Wikipedia says "modernize", but this is with hindsite) the spelling, or did they go back to Shakespeare's manuscripts and correct the spelling. There are lots of opinions, but really no one knows. The spelling changes made in the Second Folio of 1632 make me wonder if this whole u,v spelling exercise isn't just a waste of time.
Milton poem of Second Folio
A eulogy poem
by Milton that appears first in the 1632 Second Folio shows that it does
not follow the spelling convention of not using 'v' inside words. A facsimile
shows it has lots of words with a 'v' inside: 'leaves', 'unvalued', 'bereaving',
'conceiving'.
2nd Folio vs 1st Folio
I put facsimiles
of the 2nd Folio and 1st Folio in side by side browser windows and compared
a few pages from different plays. It is clear that the 2nd folio is (as
claimed) a page copy of the 1st folio. All the pages I looked at have page
layouts and line breaks that are almost, but not exactly the same.
Line lengths vary a little, so clearly the print has been reset, maybe
with a slightly different font by a different printer. There can be little
doubt that the printer of the 2nd Folio worked directly from the 1st Folio
copying it line by line. And while spelling of the 2nd Folio at first glance
looks the same as the 1st Folio, comparing lines carefully soon showed
a few (small) differences, usually associated with 'u' and 'v'. The following
are all from the 1st column of first page of Romeo and Juliet.
First Folio
I will bee ciuill with the Maids, and cut off their heads.
Second Folio
I will be civill with the Maids, and cut off their heads.
'u' to 'v' in 'civill' and 'bee' to 'be'
First Folio
To moue, it to stir: and to be valiant, is to stand:
Second Folio
To move, it to stir: and to be valiant, is to stand:
'u' to 'v' in 'move'
First Folio
That shewes thee a weake slaue,
Second Folio
That shewes thee weake slave,
'u' to 'v' in 'slave' and 'a' omitted
First Folio
Do you bite your Thumbe at vs sir?
---------------------------------------
Do you bite your Thumbe at vs, sir?
Second Folio
Doe you bite your Thumbe at vs sir?
---------------------------------------
Doe you bite your Thumbe at us sir?
'v' to 'u' in 'us', but only on 2nd line,
'Do' to Doe', and comma omitted in 2nd line
The entry above is interesting, because the line ['Do you bite your Thumbe at vs sir?] is in the text twice. In the first folio the text and spelling of the two lines is exactly the same (second time an added comma), but in the Second Folio we find a spelling difference: 'vs' and 'us'.
From first page, 2nd column of Julius Caesar
First Folio
Haue you not made an Vniuersall shout,
That Tyber trembled vnderneath her bankes
To heare the replication of your sounds,
Made in her Concaue Shores?
Second Folio
Have you not made an Vniversall shout,
'u' to 'v' in 'have' and 'Vniversall'
That Tyber trembled underneath her bankes
'v' to 'u' in 'underneath'
To heare the replication of your sounds,
Made in her Concave Shotes?
'u' to 'v' in concave, and 'shores' to 'shotes'
Second Folio's u,v usage
In a side by side
comparison of just two pages of the First and Second Folios the u,v pattern
is clear. The u,v Shakepearean (?) pattern of the First Folio is all changed.
The Second Folio published only nine years after the First Folio now uses
'v' inside words where in modern spelling a 'v' consonant appears, like
'have' and 'move', and 'u' is now used to start words, like 'underneath'
and 'us', replacing the 'v' first letter of the First Folio. Note, however,
that the capital 'V' in 'Vniversall' remains.
The Second Folio looks to have been poorly proof read. Change of 'shores' to 'shotes' looks like a typo ('concave shores' appears in modern editions), and one instance of 'vs' remained while two lines away it was changed to 'us'. The omission of 'a' in the line [That shewes thee a weake slaue (1st folio)] also looks like a typo.
Second folio references
Scholarly
paper below discusses variants. Shows five different title pages, on one
title page 'according' is spelled wrong ('according').
http://digital.lib.lehigh.edu/eb/supp/2073/index.pdf
YouTube video
of auction house with a copy they were going to auction (estimated sell
price 200k to 250k). They describe it as page for page reprint of First
Folio.
http://www.youtube.com/watch?v=bzCSiaYLpgw
Wikipedia 'Second Folio' says there are 1,700 changes from First Folio.
An aside --- Two facsimiles of First Folio===========================================================================================================
While looking at facsimiles of the 1st Folio and 2nd Folio, I was appalled to see how poor some of the facsimiles are. The bleed through from the ink on the reverse side of the page is so bad on some they are barely readable. Here are facsimiles of two different copies of the First Folio from the same site.
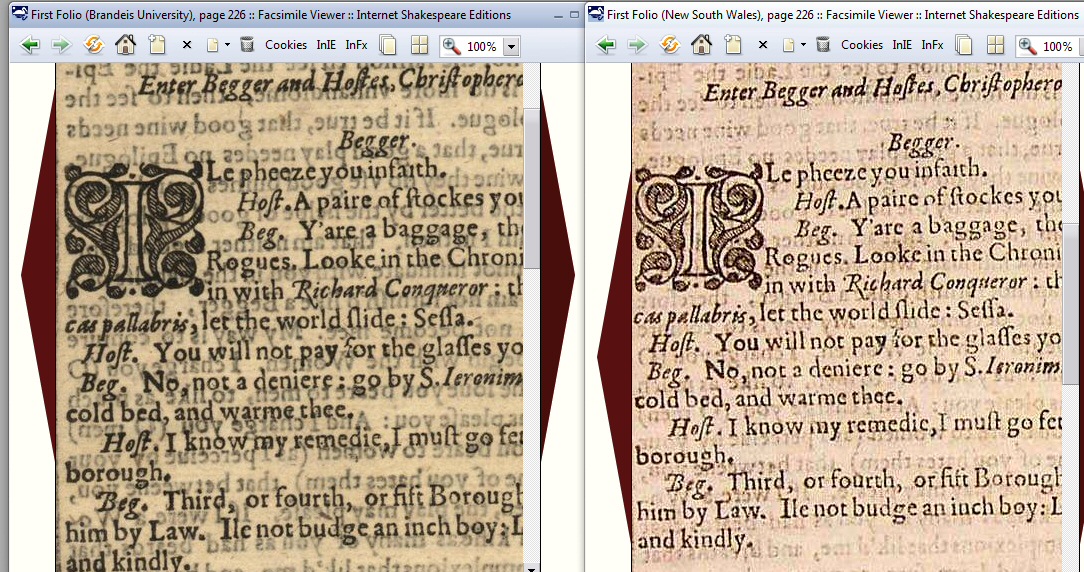
First page of 'The Taming of the Shrew' from two copies of First Folio
Bleed through of the facsimile of First Folio at Brandeis (left) is really bad
source -- http://internetshakespeare.uvic.ca/Library/facsimile/bookplay/Bran_F1/Shr/?zoom=5
source -- http://internetshakespeare.uvic.ca/Library/facsimile/book/SLNSW_F1/226/?zoom=5
Is there a cryptogram by Shakespeare?
I finally decided James
Ferris' recent finding of a (potential) skip cryptogram in the sonnets
looked too interesting to exclude from this essay. It's been relegated
to an appendix not because I think it uninteresting, but because the writing
was nearly finished and it falls in a different class. For one thing, it
arises from much more text than the other cryptograms I discuss. The sonnets
as a group have nearly 70,000 letters, almost x500 more than the sonnet
dedication. This shifts the odds, making longer strings more likely to
arise by chance. And two, the author of this (potential) cryptogram is
not some contemporary of Shakespeare, but is presumed to be the famous
poet himself, William Shakespeare (or de Vere).
Critical
look at sonnet 76
Dr. James
S. Ferris made a recent (2008) discovery in sonnet 76 that has been widely
referenced in the Oxford cryptographic community. On an x14 grid of the
sonnet 76 he found immediately below the poem words 'my name' (hor)
the six letter string 'devere' (vert) (see below, left). Ferris sees this
as a linking of Oxford's name, 'de Vere', to 'my name', which appears in
the well known line of sonnet 76, 'That euery word doth almost fel my name'.
Ferris asks, 'Why would the Stratford William Shakespeare say: "My Name
is Ed de Vere"?'
Mathematically this does look (at first glance) like it could be pretty strong. One, a six letter string is quite long, so odds of it forming by chance would be low, at least if the source text is short, which here it may not be. Two, the placement of the ''devere' string abutting 'my name' is probably the most striking feature of the grid. It does look quite unlikely, and a product of two rare occurrences will yield high odds. A hidden 'devere' abutting 'my name' in the text does look so surprising that it requires, demands really, a hard, critical look be taken at this apparent cryptogram. And that is what I propose to do in the rest of this appendix.
 .
. 
(left) Ferris' x14 grid of sonnet 76 (used with permission)
(right) my little sketch showing alternate strings and placement
(source left ---
http://www.drjsferris.com)
I see a bunch of issues here.
1) Motive
It's generally
thought that the sonnets were not written for publication, but of course
nobody really knows. If they were written for Shakespeare's intimates,
what would be the point of Shakespeare identifying himself by encrypting
his name into the sonnets? Maybe a lark, word play? Shakespeare is
famous for word play in his plays, but this doesn't really fit with the
serious nature of the sonnets, does it? To me the lack of an obvious motive
for this being done deliberately is big problem with this potential cryptogram.
In some unquantifiable way it increases the odds that the finding has occurred
by chance.
2) Cryptogram is not really clean
Look at Ferris's
figure (left), the alignment of 'my name' and 'devere' looks pretty striking,
right? Must be deliberate, right? But look again, it's not
really that clean. Reading it in the most logical way (hor and then down)
it reads ' 'my name' followed by 'ereved'. 'Devere' is reversed (it
has to be read vertically upward), and it's not very well centered either.
To illustrate this, and a bunch of other possible alignments and string
variants, I drew the little sketch above right. I marked what to me is
a cleaner version, reversing 'ereved' to get 'devere' and better centering
it under the phrase 'my name'.
Maybe you don't agree. Many Oxford decoders seem to have no problem reading down or up, whatever works to get a message seems to be the practice, but to me the alignment of the hor and vertical words in the x14 grid of sonnet 76 is just not that clean. If horizontal 'my name' is the beginning and below it is the hidden (vertical) name, then I argue that the logical English style reading of the hidden name is downward.
Even cleaner would be finding 'devere' in sonnet 136Come on Will!
Sonnet 136 also has the words 'my name' in the text, but here we find it linked to 'Will'. The relevant half line is, 'for my name is Will' (capitalization and italic in the original, see facsimile below). This appears to be the author of the sonnets explicitly identifying himself as 'Will'.Now if the author, who the Oxfordians think is the Earl of Oxford, had really wanted to leave a powerful hidden message, why didn't he in effect override the 'Will' reference by abutting a hidden 'devere' to 'my name' in sonnet 136? Would this not be far more impressive, ironic, and cleaner than the finding in sonnet 76? I think so, but alas this is not what was found.
3) Not decoded with Shakespearean spelling
There is little
doubt that in some sense 'u' and 'v', which had not yet split into separate
letters of the English alphabet, were (in some sense) interchangeable in
Elizabethan writing. The Oxford decoders seem to then immediately jump
to the conclusion that a 'u' to 'v' switch-aroo is perfectly justified
when decoding. After all they were equivalent in Elizabethan english weren't
they?
'u' to 'v' switch-aroo
The table below
shows the 11 different words found in sonnet 76 that include a 'u' or 'v'.
Some are used multiple times, they are the basis for the 14 'v' words in
Ferris' grid of sonnet 76. Shakespeare's spelling of 'u,v' words was remarkably
consistent across his main body of work: Venus & Adonis, sonnets, the
First Folio. The first column shows the spelling Shakespearean always used,
based on facsimiles. The second column shows how the word is spelled in
Ferris' x14 decode grid (above). Clearly what Ferris as done is change
all
'u's to 'v's, but in so doing he is not decoding with the words spelled
as Shakespeare spelled them!
This is a very
important point. Ferris is not decoding with Shakespearean spelling!
12 of the 14 'v' words in Ferris' x14 grid are spelled differently
from the spelling found not just in sonnet 76, but the spelling found in
any of Shakespeare's works. And this change made by Ferris is what provides
the 'V' in de Vere (string 'ereved'). The decode starting point is a grid
with altered spellings, then the claim is made that the name uncovered
has been deliberately put there by Shakespeare. What? To me this kind of
cryptographic fudging undermine the whole decoding effort of sonnet 76.
|
sonnets First Folio |
x14 grid (by Ferris) |
spelling? |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Of course, skeptical me suspects the real reason for the 'u' to 'v' switch-aroo is to increase the number of 'v's on a grid making 'Vere', usually the prime target of the Oxfordians, more likely to be found. I ask (I just ask, I do not know the answer), does this 'u', 'v' interchangability apply to proper names too, like de Vere? It has been argued by some Oxfordians that 'de Uere' is equivalent to 'de Vere'. Well if it is, why is the first step in Ferris' decoding, both with the sonnets and First Folio poem, to switch 'u's to 'v's? A Google search for "de Uere" does have some hits, but this is weak support for the idea that it is an equivalent alternate spelling of 'de Vere'.
Zero Google hits
As I pointed out in an appendix above, doing a 'u' to 'v' switch-aroo, as Ferris does in the last line of the First Folio epitaph poem,[Not on his Picture, but his Booke] => [Not on his Pictvre, bvt his Booke]
reduces the Google hit count for this phrase from 12,900 to 0. The likely reason for 0 hits is that Shakespeare never in any of his works spelled 'but' as 'bvt' or 'picture' as 'pictvre'. This can be verified by a search of Shakespearean facsimiles (link below). This tells me that the justification for doing a 'u' to 'v' switch-aroo is pretty weak. It can be argued that hardly anyone but Oxfordian decoders looking for 'Vere' are doing it.
Below is a facsimile of sonnet 76 as published in 1609. 'v' is found as first letter of its words 'verse' and 'variation'. Inside words, where in modern English would be a 'v', we find a 'u', for example: 'loue' for love, 'euery' for every.An aside --- Shakespeare's boot licking dedications
The text of the Venus and Adonis dedication must be a huge embarrassment to those who admire Shakespeare as a writer. If it is not a jest or inside joke, which it might be if the author is de Vere since in the year Venus and Adonis is published (1593) Lord Burghley is trying to arrange a marriage between one of de Vere's daughters and Wriothesley, it shows Shakespeare to be quite a boot licker since Henry Wriothesley surely has no achievements in his life at this point, in 1593 he is just 20 years old, except for his birth. The dedication of the Rape of Lucrece a year later, also to Wriothesley and also signed by Shakespeare, continues the boot licking. (However, I admit that similar bootlicking dedications can be found by Galileo in his books, but at least in his case there was an obvious purpose.)

'v' can be found as first letter of a word ('verse',
'variation')
inside words a 'u' substitutes for 'v' ('loue' for
love, 'euery' for every)
The Sonnets, Quarto 1, 1609 (Chalmers-Bridgewater
(Aspley Imprint))
source -- http://internetshakespeare.uvic.ca/Library/facsimile/book/UC_Q1_Son/36/?zoom=5
Why u,v confusion in sonnet 76 cryptogram?
I ask, if sonnet
76 contains a deliberate cryptogram done by old Will, why the 'u', 'v'
confusion? In Ferris' finding the 'v' of 'de vere' comes from 'loue' after
it has been modified to 'love'. If this word is the anchor for a deliberate
encoding of 'Vere', why do we find it spelled with a 'u' in the 1609 sonnet
when a 'v' is called for? I suspect the Oxfordians are now rolling their
eyes as they seem to think 'u' and 'v' are fully interchangeable, but to
me this is a problem, a serious problem with the decoding of this sonnet.
To get out a hidden 'de Vere' it must be decoded not using
Shakespearean spelling! This just does not smell right.
It's a potential confusion that Shakespeare could have easily avoided. All he needed to was work into the text a single word beginning with 'v' at the right spot, like maybe reuse 'verse' from the first line. This is a change of one word in all 154 sonnets to cleanly hide his name! Was Shakespeare so incompetent a poet that he could not arrange for a word beginning with 'v' to appear in the one location of sonnet 76 where he needed it to form 'devere'? Are the Oxfordians going to argue this was just too tough for old Will, the world's greatest poet? That's a tough sell.
Note to the printer option4) Why is the potential cryptogram not robust?
Shakespeare didn't even need to tweak the text. With an instruction to the printer (a scribbled note on the manuscript is all it would take) he could have snuck in a 'v' trivially. If Elizabethan spelling was so flexible and fluid as the experts say, why didn't Shakespeare just switch the 'u' in 'loue' to a 'v'. Who would notice?Spelling change as cryptogram key
The argument can be taken further. Suppose someone does notice, then this (odd) shift in spelling, different from his usual consistent spelling, becomes a key (or hint) that a cryptogram might be present!
Why not 'de Uere'?
I have been
heard the Oxfordian claim that 'de Uere' is basically the same as 'de Vere'.
Really? Why then, I ask, does Ferris first switch all the 'u's to 'v's
before he writes out his grids? Skeptical me, but I suspect the answer
is that if he were to publish a grid with a vertical 'ereued' string, it
just wouldn't look very impressive.
The history of u,v in the English alphabet (see Wikipedia 'u' and 'v') gives more reasons to be skeptical of 'de Uere'. In the appendix 'Shakespearean spelling' I list three reasons why is must be 'de Vere' and not 'de Uere'. One, 'u' is used only inside words, two, no capital 'U' exists at this time, and three, first letter of 17th Earl of Oxford's name begins with a consonant, and 'v' is evolving to be the consonant and 'u' the vowel.
5) Cryptographic fudges
Notice the
apostrophe between E and S in Ferris' grid. This supports his reading of
this hidden message as 'My Name is de Vere'. Nice english, but where did
the apostrophe come from? Ferris just put it in! And where did most
(12 of 14) of 'v's in his x14 grid come from? Ferris switched all
the 'u's in the original sonnet to 'v's. Look at his Ferris' published
grid (above). It does not have a single 'u', but the facsimile of sonnet
76, and all the sonnets, are full of 'u's. The original spelling of 'loue'
has been changed to 'love' to provide the 'v' to anchor 'Vere'.
This kind of free or creative decoding is seen again and again in Oxfordian decoding. Readings are up, down, or horizontal, whatever works. Letters are switched, word order is changed. The members of the small cryptographic community who search for hidden messages in Shakespeare or related documents seem to have convinced themselves that this kind of creative or free decoding is perfectly OK. It's all about "context", it is argued. And of course you get more and cleaner messages! I remain unconvinced.
The problem I have with this approach to decoding is that it is too subjective, and too reminiscent of the self-delusion and sloppiness that led the Baconian decoders into the wilderness a century ago. A rereading of the Friedmans' excellent book of fifty years ago I think is useful. The bias I see is that these decoders, mostly supporters of de Vere as Shakespeare, want to find messages. Their decoding is not neutral. When what looks like a message pops up, they see it as perfectly acceptable to 'clean it up' a little. But this tweaking eats away at the mathematical odds calculation, which is essential for estimating the risk that a finding might pop up by chance.
Corollary --- The corollary of this attitude, which I almost never see stated, is that the encryptors, and in the case of the sonnets we are talking about one of the most famous writers of all time, were either just not very competent at encoding, or else couldn't be bothered to do it right. Was it beyond them? Didn't they really care? A rough message does the job? I don't see a credible argument that 'cleaning up' of (supposed) messages is acceptable decoding practice.
6) Sonnets are a lot... of text
A major, crucial
factor in the calculation of odds (that a specific result will occur by
chance) is the length of the original text to be searched. A (potential)
cryptogram located in the sonnets is not like the other cryptograms discussed
in this essay. Why do I say this? At 448 letters isn't sonnet 76
only modestly longer (x2 to x3) than the length of other cryptogram texts
discussed in this essay? Yes, but the length of sonnet 76 is not the point.
There are 154 sonnets, of which sonnet 76 is typical. How much text is
this? Well sonnet 76 has a little less than half a thousand letters, and
there are 154 sonnets, so this is a searchable text length of 70,000 letters
(round numbers), and since each sonnet can be written out in about 44 different
grids, this is a total of about 6,800 grids!
In other words what looks like the surprising finding of x14 grid of sonnet 76 doesn't seem quite so surprising when it is realized that it has been selected out of not a few dozen grids, as is the case with the other cryptograms discussed in this essay, but from something like 6,800 grids. Well isn't that a little unfair? After all we have the joining (sort of) of de Vere's name (well, really the string 'ereued') with the text words 'my name'? Well for one thing 'my name' is identified after the fact. How many other phrases could have been woven in (he is, I vow, I am, look here, etc, etc)? I'm betting a creative decoder can be, well, creative.
Doesn't 'my name' only occur in sonnet 76? Nope, 'my name' occurs 5 times in 4 different sonnets: 72, 76, 111, and 136 (twice). ('name' is found 14 times in the sonnets.)
7) Sonnet 136 says, "my name is Will"
In the sonnet
136 we find a 'my name' reference that appears to contradict the 'my name
is de Vere' cryptogram solution of sonnet 76. The text of sonnet 136 looks
like a clear message from the author about who he is (and 'is' is actually
there, not inferred). The relevant text in sonnet 136 is:
Make but my name thy loue, and loue that still,
And then thou louest me for my name is Will.

Last two lines of sonnet 136
with two 'my name' including
"my name is Will"
(source -- http://internetshakespeare.uvic.ca/Library/facsimile/book/UC_Q1_Son/61/?zoom=5)
Note 'Will' is emphasized in the 1609 facsimile: capitalized and initalics ('my name is Will'). The message in the text about who the author is seems pretty clear. So how come de Vere didn't override the text message (so to speak) by encrypting his name in this sonnet and abutting it to this 'my name'? Speculative, but still I think an interesting question, and another indication that maybe de Vere did not deliberately insert his name in sonnet 76, because it was the wrong 'my name' in the wrong sonnet.
8) Auxiliary hints are thin
The auxiliary
hints are thin (to non-existent) in the case of sonnet 76. There's nothing
special about x14 grid. Decoders of other texts have pointed to oddball
spellings in the text as a hint it might be a cryptogram, but there are
no oddball spellings in sonnet 76 that anyone has noticed. Ferris doesn't
mention any, I don't see any. Shouldn't the lack of spellings hints count
as a negative? There's really nothing special about sonnet 76 either, since
'my name' occurs in several sonnets. I suppose it could be argued that
its context "Doth almost tell my name" is a hint, but as I argue (above)
the context of 'my name' in sonnet 136, 'my name is Will', I find
more compelling.
9) Calculate odds from a universe of possibilities
It's common
in the cryptographic literature to see the calculation of odds for exactly
what
has been found. This generally gives the highest (most impressive sounding)
number number, and from one point of view it seems 'right', because after
all this is what was found. But from another viewpoint, this number is
meaningless. It doesn't really answer the important question, What are
the odds that our finding, which comes from a universe of similar (effectively
equivalent) possibilities, could have arisen by chance.
For example, How important is it, really, that 'devere' touches the 'y', and only the 'y', of 'my name'? If it touched any letter of 'myname', would not the 'wow factor' (to quote Everybody Loves Raymond) be the same? Sure it would. What if the string read down instead of up, just as impressive? Sure. (Maybe even a little cleaner.) What if the Oxford string abutted 'my name' from above? What if the two strings intersected? Same 'wow' factor? I think so. Therefore all these locations are part of the universe of possibilities and should be included in the odds calculation.
Like quantum mechanicsFerris has calculated the odds of his exact finding, calling it the "raw probability of deliberate placement within the plaintext". He calculates the odds at 8.5 million to one (round numbers) for the vertical six letter string 'e r e V e d' located under 'y' of 'my name'. I don't disagree with his math, but my reaction is so what. This is not what is important.
I am reminded of how odds are calculated in quantum mechanics. It matters not in quantum mechanics that say, on the 34th run of the famous double slit experiment, that an electron hits the left detector. Quantum mechanics is inherently statistical. Its odds calculation proceeds by assessing the universe of all possible paths an electron can take (Feynman formulation), and calculating the fraction of this universe of paths that intercepts the left detector.This is how I think cryptogram calculations should be done. A finding is like one run of a statistical experiment. The finding arises from a universe of possibilities, by which I mean results, which if found, would have been viewed as similar (equivalent) with the same 'wow' factor. Granted this involves making some distinctions, drawing some boundaries, but it also amounts to framing the problem correctly, so that the calculated odds tell us about the risk that this type of finding is a chance occurrence.
Letter count differenceUniverse of possibilities
I do, however, disagree with one of Ferris' letter counts. He counts 8 'v', but I count 14 in sonnet 76 after his 'u' to 'v' switch-aroo (see Ferrris' x14 grid above). I get very close to his letter counts for 'd', 'e' and 'r' with my counts in the 448 letters of sonnet 76: 'd' (26), 'e' (55), and 'r' (24).) Correcting the 'v' count from 8 to 14 reduces his calculated odds from 8.5 million to 5 million.
I know 'related findings' is a little subjective, but I see no way around this. As the factors below demonstrate, it's really not that hard to define this universe. Much of it is common sense, just thinking the problem through.
Multiple locations
Just taking the six letter 'my name' (ignoring Ferris' trailing 's') gives 16 abutting locations for a vertical string (6 below, 6 above, 4 at ends). And it's not just abutting, there is also intersecting. Any of the three 'e's of the Oxford six letter vertical string could share the 'e' of 'my name'. This might be six more locations, but I will be conservative and call it three. All these locations have the same odds, so the odds of a specific string abutting (or intersection) 'my name' at various letters on a particular grid is 5 million divided by 19.
Multiple strings
How many candidate strings are there? Well there is certainly two: 'ereVed' (found) and 'deVere', equivalent to de Vere read up and down. But with proper high-liting 'de Vere' can be thought of as the four letter string 'Vere' abutted to the two letter string 'de'. So it's arguable that the following six strings, which mix up the order of 'de' and 'Vere' and reading up/dn, also fit in the de Vere name universe: 'ed Vere', 'de ereV', 'ereV de', 'Vere ed', 'Vere de', 'ed ereV. So we have a name universe of 8 six letter name strings, all containing de + vere is various up/dn combinations. Divide the odds by another factor of 8 for multiple name strings.
Multiple grids
There is nothing special about the x14 grid. There are something like 44 possible grids for a 448 letter text, so divide by 44 for multiple grids.
Multiple 'my name'sCombining
But why restrict ourselves to sonnet 76? 'My name' occurs five times in the sonnets, so divide by another factor of 5.
5 million/(19 locations x 8 strings x 44 grids x 5 'my name') = 5 million/33,000 = 150 to 1 (or 0.67%)
OK, still some modest mathematical strength remains, but the odds are not an overwhelming millions to one. It's in the ballpark of 150 to 1, about 2/3rd of a percent.
Bottom line
So is sonnet
76 a cryptogram? After considering a wide universe of similar findings,
a fairly weak mathematically case does remains, but it rests on what I
consider to be questionable cryptographic adjustments and fudging. The
case is weakened by the lack of motive, there was no obvious reason for
Shakespeare to hide his name in a document written for intimates and not
intended for publication, and the case is further weakened by the lack
of supporting hints (or keys). So while this might conceivably be a cryptogram,
the mathematics and surrounding case are so weak that I don't see how we
can have any confidence that Shakespeare (or de Vere) really encoded his
name deliberately within the sonnets.
Links
Facsimile and searchable original spelling.
http://internetshakespeare.uvic.ca/Texts/search.html?e=Son_Q1
advanced search
http://internetshakespeare.uvic.ca/Library/facsimile/index.html
facsimiles
Searchable concordance of Shakespeare's works
http://www.opensourceshakespeare.org/concordance/
http://www.opensourceshakespeare.org/search/search-advanced.php
advanced search
Essays on sonnets
http://www.williamshakespeare-sonnets.com/sonnet-76
Forum --- Vere is Shakespeare ciphers
http://www.shakespearefellowship.org/ubbthreads/ubbthreads.php?ubb=showflat&Number=51063#Post51063
========================================================================

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}